CDN详情查看我这篇文章:https://blog.csdn.net/qq_43442524/article/details/106924003
前期准备
- Centos7 四台
- Xshell
1. Squid
Squid 常常被用作代理缓存服务器,在自建CDN中处于源站和客户端的中间位置,使得用户无需访问源站便可获取内容资源,提高了用户的访问速度。作为代理服务器,Squid 可以支持多种协议,如 HTTP 、 FTP , SSL 协议等,Squid 使用 的是单独的 I/O 驱动进程来获取并响应客户端的请求,这是 Squid 独特的地方。
Squid 作为代理服务器,可以获取并响应用户的访问请求 。当用户向 Squid 发出访 问某个内容的请求时,Squid 会将用户请求转发到需要的网站,然后,网站响应该请求并将内容返回给 Squid,最后 Squid 将内容返回给用户,同时也会在本地存放一份备份内 容,以后遇到同样的用户请求时则将备份传送给用户,以此提高用户的响应速度。
由于Squid 存在己久,导致其与近年来流行的系统特性有很多不兼容之处。所以,目前很多公司在引用 Squid 的时候都会对其核心功能进行修改,比如,修改 Squid 以使得它支持多进程等。对 CDN 的提供服务商而言,也需要根据不同需求对 Squid 进行特定的修改。
虽然 Squid 存在时间比较长,也有很多特性无法支持,但是作为代理缓存服务器, Squid仍然能为用户访问网站起到很好的加速作用,并且在提高访问速度的同时,也拥有身份验证以及流量管理等高级功能。基于此,流服务缓存节点采用 Squid 实现代理缓存功能 。
1.1 安装Squid
1 | [root@localhost ~]# yum install -y squid |
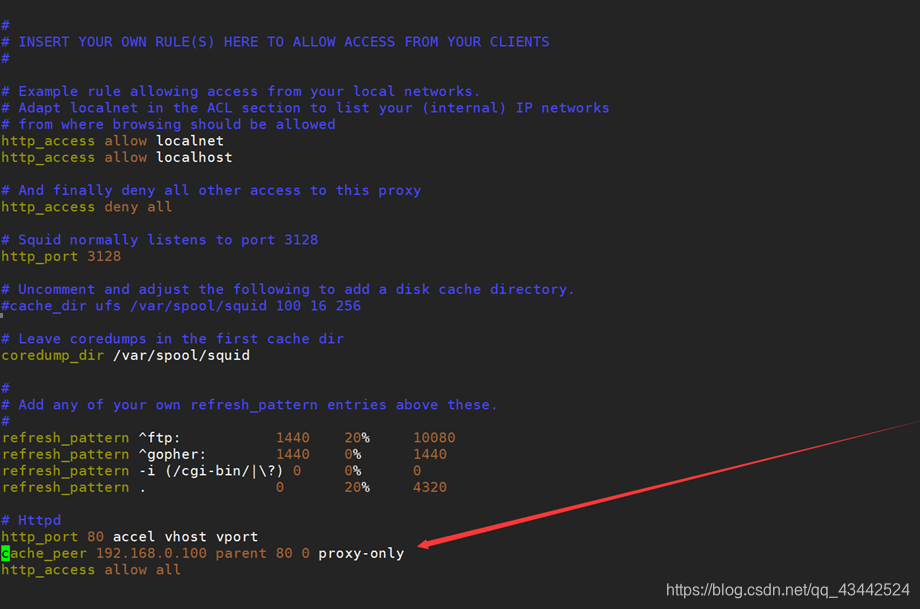
1.2 启动Squid
1 | [root@localhost ~]# squid -k parse |
2. Apache
2.1 安装Httpd服务
[root@localhost ~]# yum install httpd -y
2.2 编写首页
#index.php1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
function serverIp(){ //获取服务器IP地址
if(isset($_SERVER)){
if($_SERVER['SERVER_ADDR']){
$server_ip=$_SERVER['SERVER_ADDR'];
}else{
$server_ip=$_SERVER['LOCAL_ADDR'];
}
}else{
$server_ip = getenv('SERVER_ADDR');
}
return $server_ip;
}
<!doctype html>
<html>
<head>
<meta charset="utf-8">
<title>CDN测试</title>
</head>
<body>
<div class="banner">
<ul>
<li><img src="1.jpg" /></li>
</ul>
</div>
<div class="main_list">
<ul>
<li><a href="#">CDN测试...</a></li>
</ul>
</div>
<span> echo serverIp(); </span>
</body>
</html>
2.3 测试
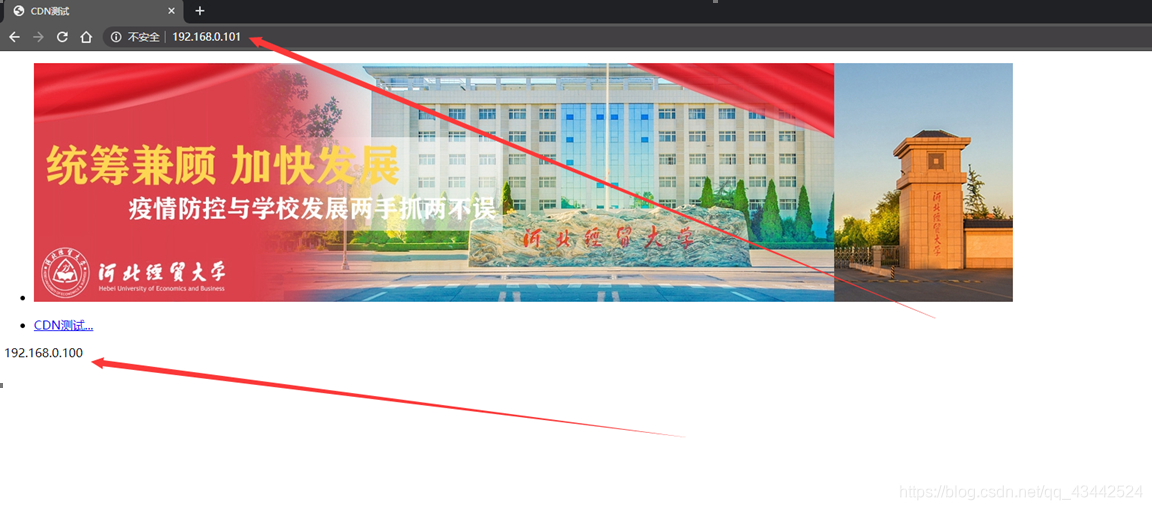
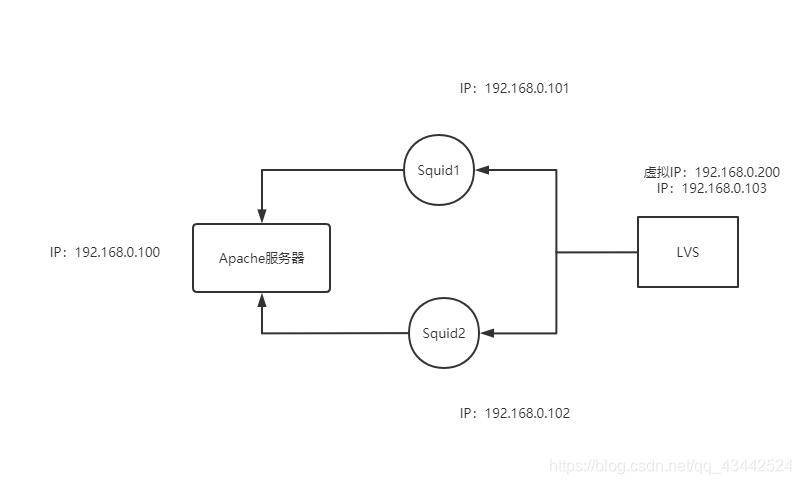
通过192.168.0.101访问到源站192.168.0.100
查看日志: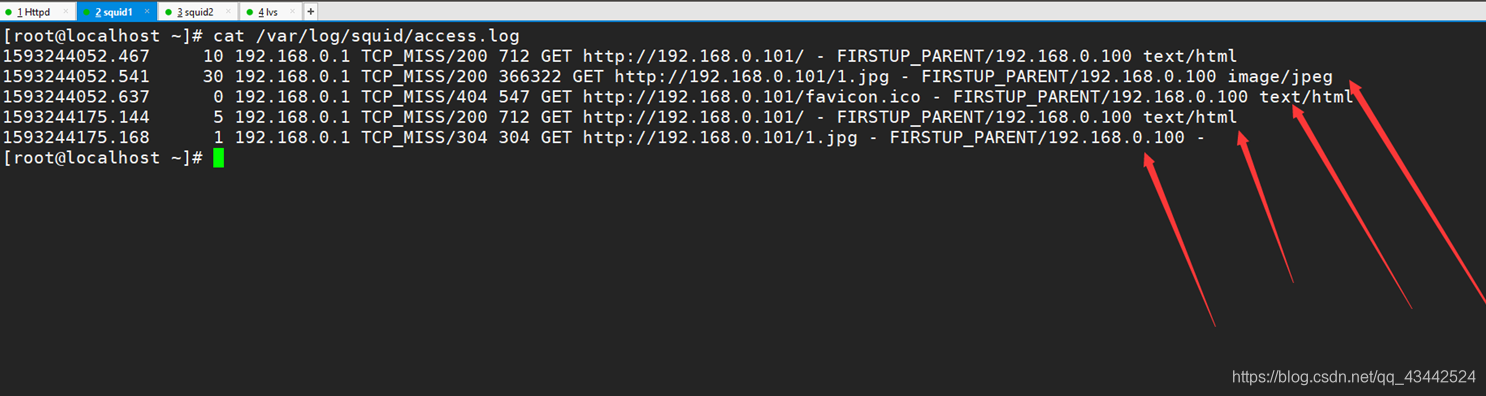
分两次访问,发现/var/log/squid/access.log
第一次访问时是从源站(192.168.0.100)拉取资源,并且在本机缓存
第二次访问,直接访问本机(192.168.0.101)资源
3. 安装LVS实现负载均衡
1 | [root@localhost ~]# yum install -y ipvsadm |
3.1 创建VIP调度地址
1 | [root@localhost ~]# ifconfig ens33:0 192.168.0.200 netmask 255.255.255.255 |
在squid1和squid2两台服务器节点,创建VIP应答地址1
[root@localhost ~]# ifconfig lo:0 192.168.0.200 netmask 255.255.255.255
在squid1和squid2两台服务器节点,屏蔽ARP请求1
2
3
4
5[root@localhost ~]# echo "1" > /proc/sys/net/ipv4/conf/lo/arp_ignore
[root@localhost ~]# echo "1" > /proc/sys/net/ipv4/conf/all/arp_ignore
[root@localhost ~]# echo "2" > /proc/sys/net/ipv4/conf/lo/arp_announce
[root@localhost ~]# echo "2" > /proc/sys/net/ipv4/conf/all/arp_announce
[root@localhost ~]#
在LVS中,#ipvsadm -L 检查配置情况1
2
3
4
5
6
7
8[root@localhost ~]# ipvsadm -L
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP localhost.localdomain:http rr
-> 192.168.0.101:http Route 1 0 0
-> 192.168.0.102:http Route 1 0 0
[root@localhost ~]#
3.2 测试
在Windows10访问(192.168.0.200),可以看到从VIP地址通过负载均衡访问到了Squid资源地址
查看日志:
宿主机通过LVS-VIP(192.168.0.200)访问到了Squid2(192.168.0.102),并且Squid2从源站(192.168.0.100)缓存了资源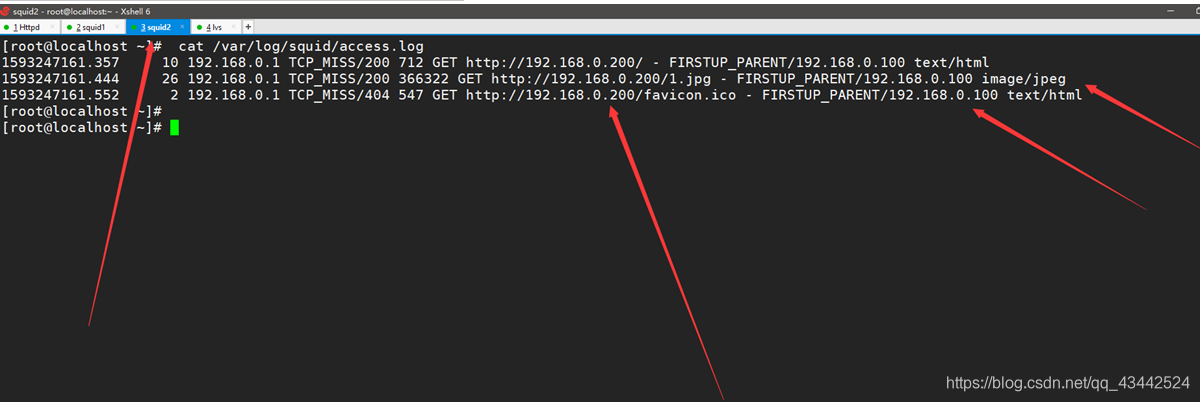
原理
此CDN方案原理就是客户端通过访问LVS暴露在外的虚拟地址192.168.0.200,将流量负载均衡到Squid1192.168.0.101或者Squid2192.168.0.102机器上,并且Squid实现了从源站192.168.0.100缓存了资源,当以后的流量想要访问源站时,直接从Squid服务器缓存中得到,大幅度减少了源站的压力。
背景
随着互联网应用的迅速发展与网络流量的大幅度激增,用户对网站的加速需求日益增长。由于 CDN 技术能够及时解决网站的响应速度问题,并对网站的稳定性起了较大的提升作用,因此受到了业界的很大关注。
不同于网站镜像的单纯内容复制,CDN 技术更加智能,可以用这样一个式子来解释 CDN 与镜像的关系: CDN=更智能的镜像+缓存+流量调度。 从上面的关系式可以看出,CDN 能够明显提高网络中数据流动的效率,从而解决网络带宽不足、 用户访问量过大以及内容分布不均等问题,提升用户的网站访问体验。 许多我国国内的网站出于业务需要,将源站服务器放在欧美地区。 这样一来,物理距离距中国太远,普遍 Ping 所需的时间都在 100ms 以上,使网站的用户会感觉到访问速率比较慢,访问体验度方面有所下降。所以 CDN 技术首先要解决的就是物理距离远所导致的访问速率降低问题。
通过 CDN 技术,在中国香港、中国台湾等地区和日本、韩国等国家部署 CDN 节点进行数据分发,即使源站放置在遥远的欧美地区,中国用户的访问速率也会得到明显的改善。 最初 CDN 的提出,就是为了通过就近提供服务来解决物理距离过远导致性能不好的问题。使用 CDN 后,网络的基本组织架构和内容传输情况发生了很大变化。从普通网站用户的角度上看, CDN 节点的作用就相当于把一个网站就近部署在用户周围。 CDN 服务器会像源站服务器一样,为用户提供需要的内容服务。但是,由于 CDN 节点更靠近用户,因而能够更快地响应用户的请求。
以视频网站为例, 使用CDN 服务后,对服务请求进行了优化调度,更加有效地利用了带宽资源,使得视频加载时间减少,性能提高。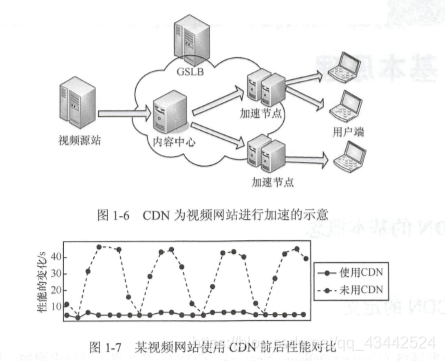
总的来说, CDN 对互联网应用的优化作用主要体现在以下几个方面:
- 缓解源站服务器访问压力,解决服务器端的“第一千米”问题
- 优化热点内容的分布,合理缓存,减轻骨干网传输的流量压力
- 提升用户的访问质量和体验,全面提高网站访问速度
- 增强网站服务的可靠性,解决网站突发峰值流量问题
- 解决不同电信运营商之间互联互通问题造成的影响
- 提高安全性,有效防止异常流量对源站的攻击
CDN 基本概念
1. CON 的定义
内容分发网络(Content Delivery Network, CDN),是在现有网络中增加一层新的网络架 构。 CDN 将源站的内容发布和传送到最靠近用户的边缘地区,使用户可以就近访问想要的内 容,从而提高用户访问的响应速度。 CDN 的基本原理是依靠放置在各地的缓存服务器,通过全局调度以及内容分发等功能模 块,将用户需要的那部分内容部署到最贴近用户的地方,将原本低效、不可靠的四网络转变成高效、可靠的智能网络,满足用户对内容访问质量的更高要求, 改善互联网网络拥塞问题, 提高用户访问网站的响应速度。
从字面意义上可以看出, CDN 的构成元素为内容 (Content)、分发(Delivery) 以及网 络(Network)。
(1) 内容
CDN 的内容通常是以下两种: 静态内容以及动态内容。
- 静态内容:内容不经常更改,并且一旦它在 CDN 缓存中,可以由许多用户进行访问,缓存性强。
- 动态内容:内容用于特定的用户或组,并且更新频率较高,通常来自源服务器并实时发送到CDN 中,缓存性较弱。对于用户的每一次请求, CDN 都必须从源站服务器拉取动态内容,所以动态内容加速的常用方法就是降低源站服务器和用户终端之间的传输时延。
(2)分发
CDN 的分发是指利用一定传送策略,将用户请求的内容发布到距离该用户最近的节点。
(3)网络
CDN 由成千上万个分布式服务器组成,通过服务器的通信,把内容分发和传送给终端用 户。
CDN 各节点之间是通过电信运营商的宽带网络进行通信的,可以说 CDN 是在电信运营 商的网络之上的一层网络。
2. CON 可承载的内容
用户在向网站发起访问请求时,如果等待一定时间网站还没有响 应,用户就会放弃访问,而镜像通常不适用于大规模商业网站加速,因此,CDN 加速需求应运而生。
静态内容是最早出现的 CDN 承载的内容类型,以文字、图片、动画等更新频率低的内容为主。
因此,CDN 技术最初就是用来对这些静态内容网页进行加速的。
后来,随着互联网的大幅度升温、宽带的普及,用户利用互联网下载所需文件已经成为一种习惯,因此, CDN 对下载业务的加速服务也是必不可少的。
近年来,大量视频网站涌现,流媒体流量随之迅速攀升,从而驱动了 CDN 技术的应用重点也逐步转为流媒体加速服务。 随着互联网技术的发展,社交网络、在线支付以及网络游戏等实时性强、内容经常更新 的互联网应用逐渐产生,因此,CDN技术也从静态内容的加速发展到动态内容的加速。
从互联网应用的角度看, 需要CDN承载的内容主要为静态内容和动态内容。
3. CDN 的工作过程
CDN 服务与传统网络服务最大的差别在于访问方式。传统情况下,用户发起访问请求后, 对于同一个内容的所有用户请求,都集中在同一个目标服务器上。
而利用 CDN 加速后,用户的内容请求解析权交给了 CDN 的调度系统,然后将用户请求引导到性能最佳的最靠近用户的 CDN 节点上, 最终该节点为用户请求提供服务。
传统的访问方式,造成了在网络中传输的极大压力,并且还无法保证用户的良好访问体验。 而使用 CDN 服务后,用户的访问请求不会集中在相同的目标服务器上,而是会分散到不同节点,在这种情况下,用户请求就不会跨地区,并且骨干网也不需要承担过重的流量负担,进而使得用户访问质量得到保证。
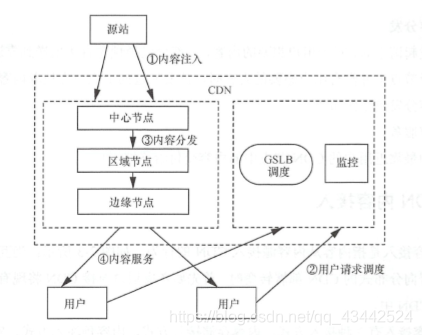
下面介绍 CDN 的基本工作过程,包括内容注入、用户请求调度、内容分发以 及内容服务这 4 个步骤。
(1)内容注入
内容注入是 CDN 能为用户提供服务的第一步,是内容从源站注入 CDN 的过程,使得用 户能从 CDN 系统中获取源站的内容。
(2)用户请求调度
用户请求调度是用户向网站发起访问请求, 最终用户被引导到最佳的有内容的 CDN 节点的过程,具体如下:
(a)当用户向网站发起访问请求时,经由本地 DNS 系统解析,本地 DNS 会通过递归方式将域名的解析权最终交给 CDN 授权 DNS 服务器 CGSLB);
(b) CDNGSLB 可将 CDN 节点设备的回地址返回用户,也可以将另一个负责解析用户 终端 IP 地址的 GSLB 设备的 IP 地址返回用户
(c)用户向 CDN 的 GSLB 设备发起内容访问请求(IP 调度方式)
(d) CDN 的 GSLB 设备根据用户 E 地址以及用户请求的内容 URL,选择一台用户所属地区的本地负载均衡 (SLB) 设备,并让用户向该 SLB 发起访问请求;
(e)该 SLB 设备通过决策选择一台最佳的服务器为用户提供服务,用户向该服务器发起访问请求;
(f) 若该服务器内容未命中,而 SLB 仍将该服务器分配给用户, 则该服务器需要向上级 节点请求内容,然后,由该服务器向用户提供“边拉边放”的服务或者由上级节点直接为用户提供服务。
(3)内容分发
当用户发起请求时,对于用户想要的内容,一部分已经预先直接推送到靠近用户的节点;
但是,当下级节点上并没有用户想要的内容时,就要通过向上级节点拉取内容的方式,把用户想要的内容分发到下级节点。
(4)内容服务
把找到的最靠近用户的 CDN 节点中的内容交付给终端用户。
4. CON 内容接入
CDN 内容接入是指内容从内容源接入 CDN 的行为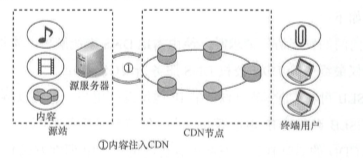
当互联网应用希望 由集中式部署向分布式的 CDN 部署转变时,首先要考虑、通过对接 CDN 将现有集中式部署的 内容转移到 CDN 中。 CDN 内容接入有 3 种接入方式:内容存储接入方式、内容预注入方式、实时回源方式,
这 3 种内容接入方式的适用场景及业务流程均有较大不同。
(1) 内容存储接入
内容存储接入指源站(互联网应用的内容源)在发布内容前,提前把内容注入 CDN。内 容存储接入方式下,业务系统需主动向 CDN 内容库发送操作指令, CDN 根据指令获得内容并存储在 CDN 内容库中,从而在终端访问 CDN 时直接由 CDN 向终端提供内容,无需再从源站获取,提升了终端用户体验。 采用内容存储接入方式接入的内容将永久存储在 CDN 中,直到通过内容接入操作指令对该内容显式删除。 CDN 的内容存储接入包括对注入内容的增加、删除和更新,能够通过业 务系统或手工方式主动发起内容删除操作并立即实现全网删除。
(2)内容预注入
内容预注入是指源站在内容发布之前将内容注入 CDN 中 。 内容预注入与内容存储接入方式类似,都是由业务系统主动向 CDN 发送操作指令, CDN 根据指令预先从内容源回源获取内容,是就近提供服务的接入方式。 但采用内容预注入方式接入的内容并不永久存储在 CDN 中,而仅仅是进行内容缓存, CDN 会根据内容访问的热度情况对缓存内容进行智能删除,预注入内容可以设定一段时间不被删除的内容保护期。采用内容预注入方式接入的内容当被缓存删除后, CDN 仍可以通过回源方式获取内容提供服务。
(3)实时回源
实时回源 (未注入〉是指源站在内容发布之前不向 CDN 注入内容,但当用户内容访问请求时, CDN 实时地从源站拉取内容。
内容回源是指对于非托管模式的内容接入,当 CDN 收到业务系统内容预注入指令或用户内容服务请求而本地没有内容时,向内容源请求并获取内容接入 CDN 的行为。
实时回源方式无需由业务系统主动向 CDN 预先注入内容,而是在终端访问 CDN 时,通过回源方式向内容源实时获取内容到 CDN 中,向终端提供后续就近缓存服务。
内容存储接入方式对用户的服务质量保障最佳,但对 CDN 的资源消耗较大,成本较高,适用于 IPTV 等对质量要求极高的业务应用。
实时回源获取方式对 CDN 资源消耗较小,成本较低, 但对用户的服务质量保障比不上内容存储接入方式, 一般在网站等业务应用上使用, 是目前 CDN 的最主要接入方式。
内容预注入方式介于内容存储接入与实时获取方式,互联网服务提供商可根据自有业务的需求选择合适的内容接入方式。
5. CON 用户请求调度
通常情况下, CDN 用户的内容访问请求调度如图 2-4 所示,分为两个层次:全局调度和本地调度
(1) 全局调度
全局调度的主要目的是根据用户所在地理位置不同,在各个节点之间进行分析决策,将 用户请求转移到整个网络中最靠近用户的节点。
全局调度方式目前主要有基于 DNS 调度方式和基于应用层重定向调度两种方式。
(2)本地调度
和全局调度系统相比,本地调度通常被限制在一定地区范围内,并且更加关注 CDN 服务器设备具体的健康状况与负载情况,根据实时响应时间,将任务分配给最适合的服务器设备进行处理,进行更精细粒度的调度决策,实现真正的智能通信和发挥服务器集群最佳性能。 本地调度的意义在于充分利用现有设备,有效地解决了用户访问请求过多引起的系统负载过重的问题。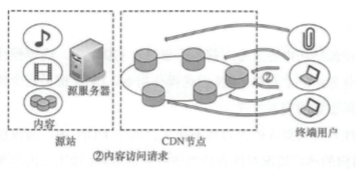
6. CON 内容分发
互联网应用的响应时间通常是由网络带宽、路由时延、网站处理能力以及物理距离等因素决定的。其中,物理距离过长对互联网应用的响应时间有最直接的影响,会使响应速度变得十分缓慢。
因此,利用 CDN 技术把最热的内容分发部署到各地的节点上。
内容为不同地区的用户提供就近服务,就能够有效地提高互联网应用的响应速度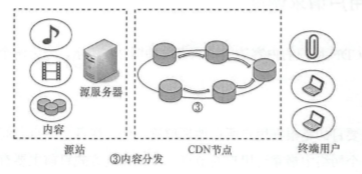
内容的分发有 Push 和 Pull 以及混合分发共 3 种实现方式。
(1) Push 方式
Push 是一种主动分发的方式。通常, Push 由 CDN 内容管理系统发起,将内容从源站或 者中心内容库主动分发到各边缘的 CDN 节点,分发的协议可以采用 HTTP、 FTP 等。通过 Push 分发的内容一般是比较热点的内容,这些内容通过 Push 方式预先主动分发到边缘CDN 节点,可以实现有针对性的内容提供。对于 Push 分发需要考虑的主要问题是分发策略,即在什么时候分发什么内容。 一般来说, Push 分发是一种智能的主动分发策略。 可以通过用户访问的统计信息(例如, 热度级别排序信息)和己经预先设定的内容分发的规则,智能地决定是否进行内容主动分发。 并且可以根据用户历史访问数据等,建立回归模型,对于智能预测用户可能会大量访问的内容,将其提前推送到边缘节点。
(2) Pull 方式
Pull 是一种被动的分发方式, Pull 分发通常由用户请求驱动。 当用户请求的内容在本地 的边缘 CDN 节点上不存在(未命中)时, 该 CDN 节点启动 Pull 方式从内容源或者其他 CDN 节点实时拉取内容, 并且在 Pull 方式下,内容是按需分发的。 在实际的 CDN 系统中, 一般两种分发方式都支持,但是根据内容的类型和业务模式的 不同,在选择主要的内容分发方式时会有所不同。通常, Push 方式适合内容访问比较集中的情况,例如,热点的流媒体视频内容: Pull 方式比较适合内容访问分散的情况。
(3)混合分发方式
混合分发方式就是 Push 与 Pull 分发方式结合的一种机制。混合分发方式有多种方案, 最常见的混合分发机制,是利用 Push 方式进行内容预推,后续则使用 Pull 方式拉取。 混合分发方式能够根据当前内容分发系统中的内容服务状况,采用推拉的方式动态地调 整内容在内容分发系统中的分布,对于热点内容主动将其推送(缓存)到边缘节点。
典型的CDN架构与组网
1. CDN 功能平面
CDN 从功能上可以划分为包含管理平面、调度平面和数据平面在内的 3 个逻辑平面。
其中,在管理平面的管理和控制下实现内容分发和推送,在调度平面完成用户请求的调度、控制以及各种内容调度策略,在数据平面实现内容分发与服务实体。
CDN 管理平面主要用来完成业务管理、网络管理、分发策略管理、 内容接入管理以及回源分发管理等一系列管理功能,管理、监控并保障 CDN 承载业务的高效运营。
CDN 调度平面主要实现用户服务请求调度(包括 DNS 调度、 HTTP 调度、 RTSP 调度)内容定位、内容路由等功能,通过控制用户服务请求的调度,实现对用户的就近及有保障的服务。
CDN 数据平面主要是内容分发与服务实体,主要负责为用户提供内容分发与应用服务, 包括内容存储、 内容缓存、内容分发、内容转码、内容服务等功能。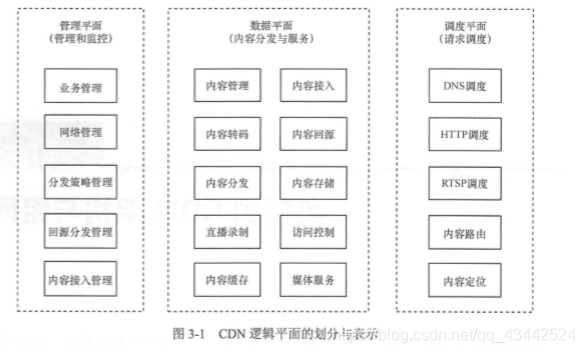
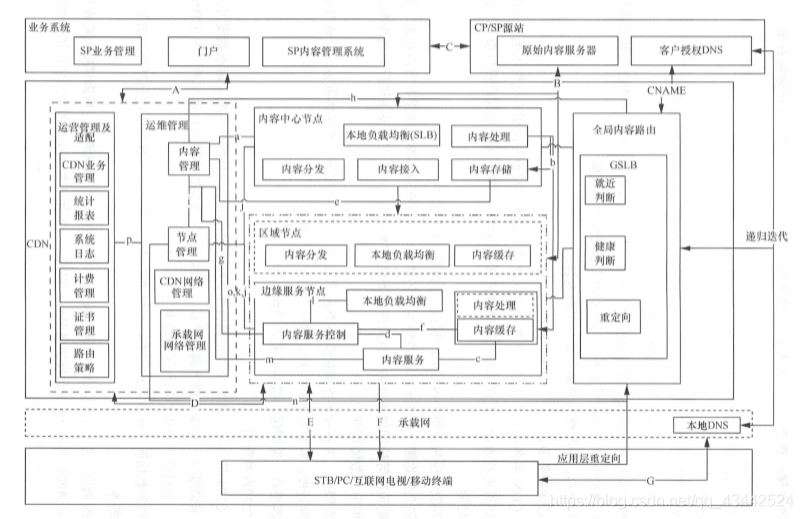
CDN 部署架构
节点是指多台物理设备在某地理区域范围内作为一个整体对外提供内容服务。每个 CDN 节点通常包含多台服务器设备,节点是 CDN 系统最基本的组成单元。 CDN 系统设计的主要目标是尽量提高用户请求的响应速度,为达到这一目标, CDN节点部署的原则是尽量将内容存放在最靠近用户的位置。
通俗地说,就是将为用户提供实际内容服务的服务器部署在网络的边缘位置。 中心节点层保存着完整的内容副本,当用户请求的内容在边缘层未命中时, 中心层可能会为用户直接提供服务,也可能由下级边缘节点向中心节点请求拉取内容,再分发到边缘节点为用户提供直接服务。但是,当用户请求量过大时,若大量边缘节点都直接向中心节点请求拉取内容,会造成中心层压力过大,这时,就需要考虑在边缘节点层和中心节点层之间部署一个区域层。区域层保存了部分内容副本,使其能够分发内容并在边缘节点未命中时提供服务,以减轻中心节点的压力。这样,就形成了 CDN 的三级系统架构。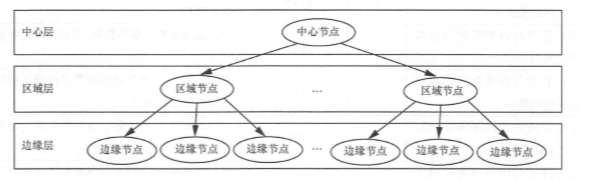
从节点构成的角度来说,无论是 CDN 区域层节点还是 CDN 边缘层节点,都是由缓存设 备和本地负载均衡设备( SLB)构成的。在一个 CDN 节点中,缓存设备和本地负载均衡设备 的连接方式有两种: 一种是旁路方式,另一种是穿越方式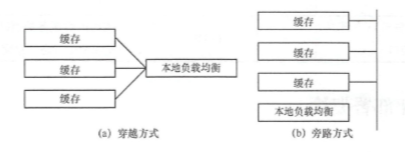
在穿越方式下, SLB 一般由四七层交换机实现, SLB 向外提供可访问(公网〉的虚拟 IP (VIP)地址,每台缓存设备分配不同的私网 IP 地址,该 SLB 连接下挂的所有缓存设备构成一个服务单元。所有用户请求经由该 SLB 设备,再由该 SLB 向上向下进行转发。 SLB 实际上承担了网络地址转换(Network Address Translation, NAT)功能,向用户隐藏了各台缓存设备设备的IP地址。这种方式是 CDN 系统中应用较多的方式,优点是具有较高的安全性和可靠性,但是,当节点容量大时,四七层交换机容易形成性能瓶颈。
在旁路方式下, SLB 有两种实现方式。 在早期, SLB 一般由软件实现。 SLB 和缓存设备都具有公共的 IP 地址, SLB 和缓存是并联关系。用户需要先访问 SLB 设备,然后再以重定 向的方式访问特定的缓存。 这种实现方式简单灵活,扩展性好,缺点是安全性较差,而且需要依赖于应用层重定向 。 随着技术的发展,四七层交换机也可采用旁路部署方式,旁挂在路由交换设备上, 数据流量通过三角传输方式进行转发。
CDN 间组网
当 CDN 覆盖范围或能力不足,或需要多厂商时, CDN 可以进行组网。不同 CDN 的共同组网目标是实现 CDN 分发与服务能力的共享,各 CDN 通过标准接口实现互联互通。 CDN 共同组网根据服务的场景及各 CDN 的功能与性能不同,可选择不同的组网架构, 典型的组网逻辑可分为以下两种。
(1)并联组网
源站同时接入多个 CDN,边’过用户请求调度层面进行流量分配,不同 CDN 共同承载内容。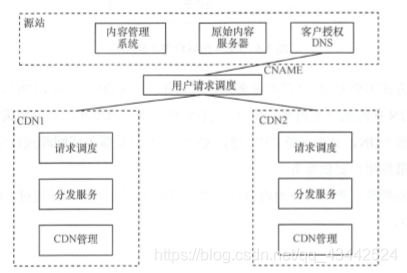
并联组网方式需要把用户流量通过 CNAME 引导到一个用户请求流量调度系统,由该调度系统把请求分配至不同 CDN。 不同 CDN 间不进行内容的分发与服务互联,均需与源站系统进行互联的实现内容注入,或分别回源获取内容,再独立进行分发服务。在一个区域内引 入多家 CDN 服务提供商向用户提供 CDN 服务时, 一般采用这种组网方式。
(2)级联组网
源站接入上游 CDN,上游 CDN 再进一步和下游其他 CDN 对接,上游 CDN 和下游 CDN 除调度层面外, CDN 内容分发与服务层面也进行互联,共同组成一张统一的 CDN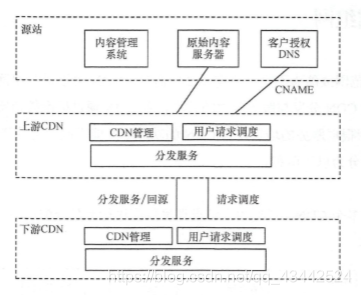
级联组网方式需要 CDN 承载的业务系统只对接一个 CDN (上游 CDN),向该 CDN 注入 内容或由该 CDN 向源站获取内容,并由该 CDN 决定用户调度和内容分发策略,把用户请求调度到其他下游CDN, 再由下游 CDN 通过 CDN 间的分发服务或回源接口实现上下游 CDN 间的互联,向最终用户提供服务。 为保证服务质量,需要服务的内容也可以通过内容预注入的方式通过上游 CDN 提前注入下游 CDN 中。
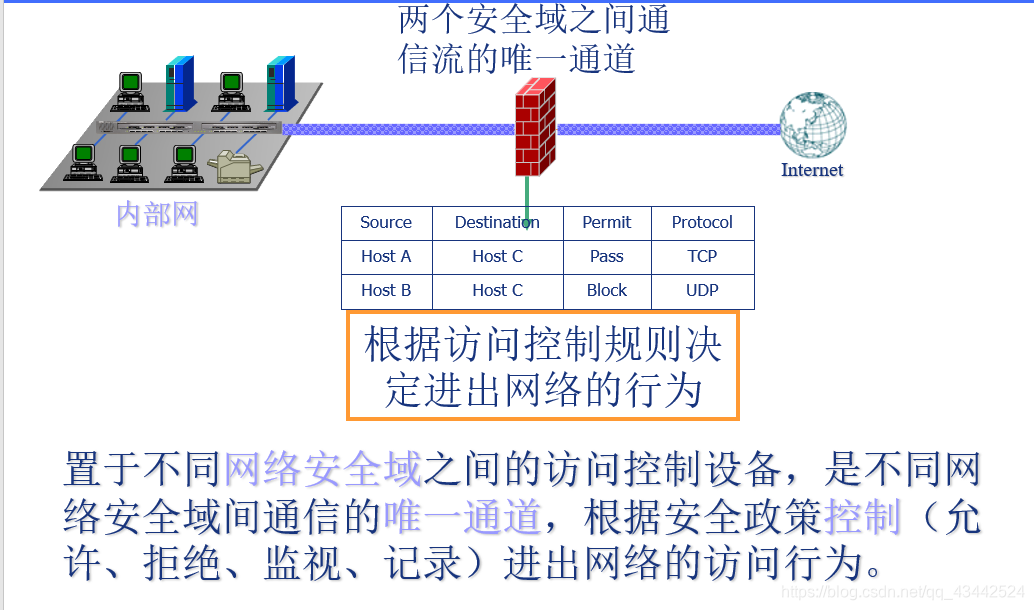
]]>防火墙定义
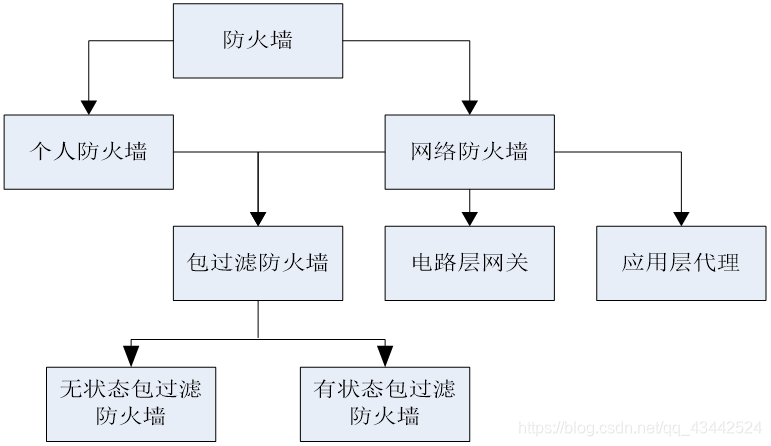
防火墙分类
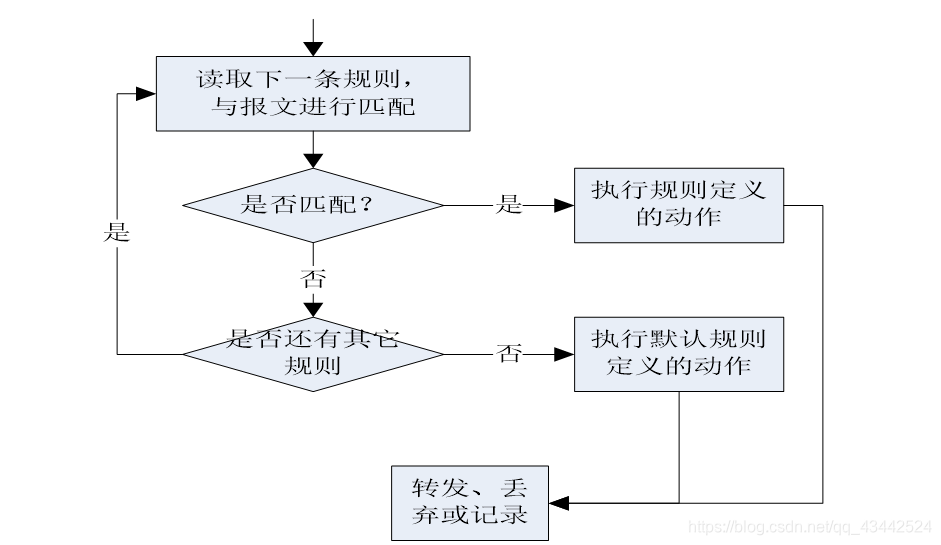
无状态包过滤防火墙
基于单个IP报文进行操作,每个报文都是独立分析
- 默认规则
- 一切未被允许的都是禁止的
- 一切未被禁止的都是允许的
- 规则特征
- 建立报文的会话状态表,利用状态表跟踪每个会话状态对于内部主机对外部主机的连接请求,防火墙可以认为这是一个会话的开始
- 访问控制策略
- 报文流动方向和所属服务
- 发起会话和接受会话的终端地址范围
- 会话各阶段的状态
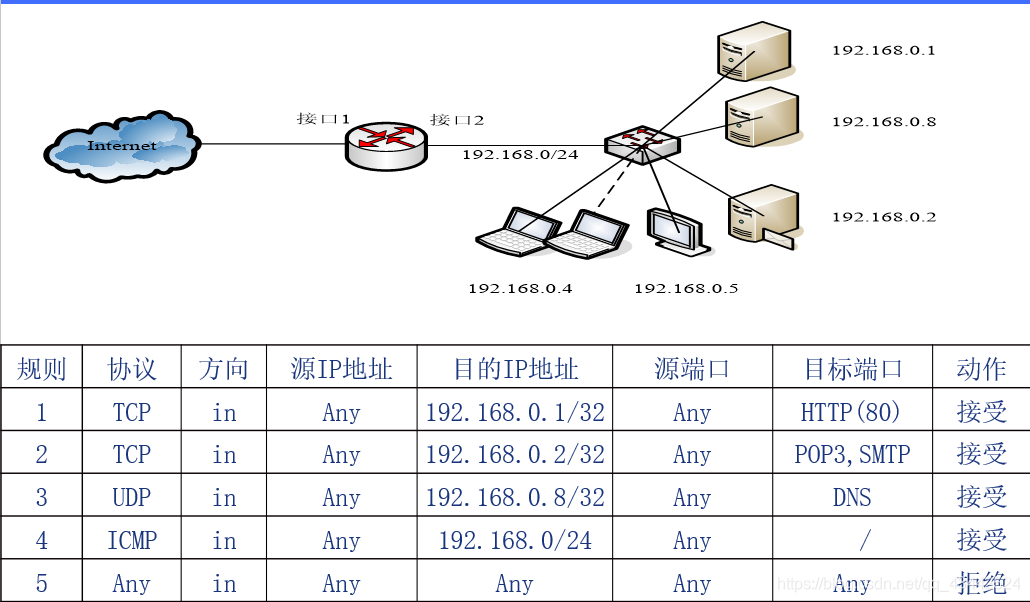
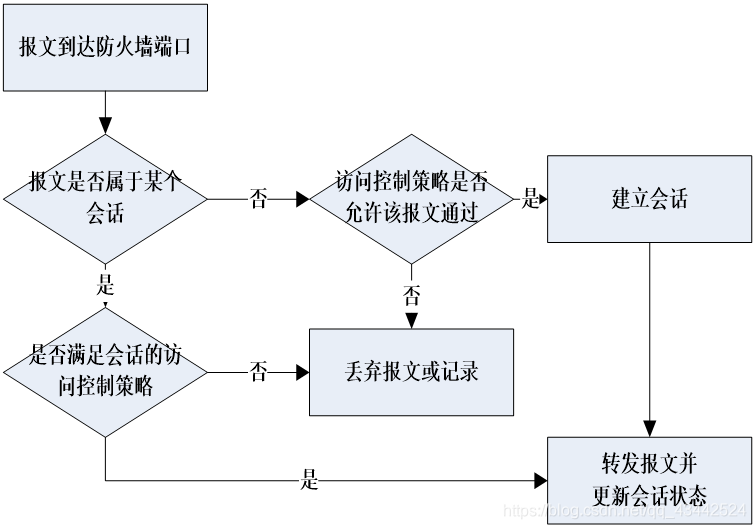
会话状态表
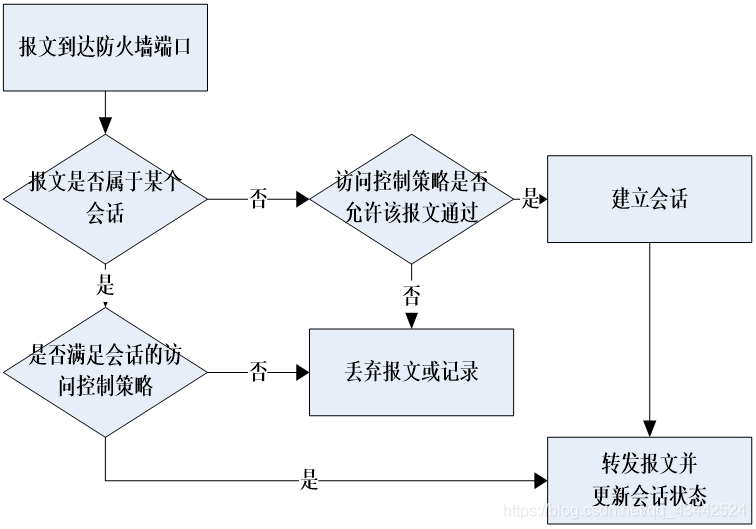
代理防火墙分类
应用层代理
- 为特定的应用服务提供代理服务,对应用层协议进行解析,也称为应用层网关
- 优点是实现用户控制、可以对应用层数据进行细粒度的控制,缺点是效率较
低电路层代理
- 工作在传输层,相当于传输层的中继,能够在两个TCP/UDP套接字之间复制数据
- 可以同时为不同的应用层协议提供支持
- 无法提供应用层协议的解析和安全性检查
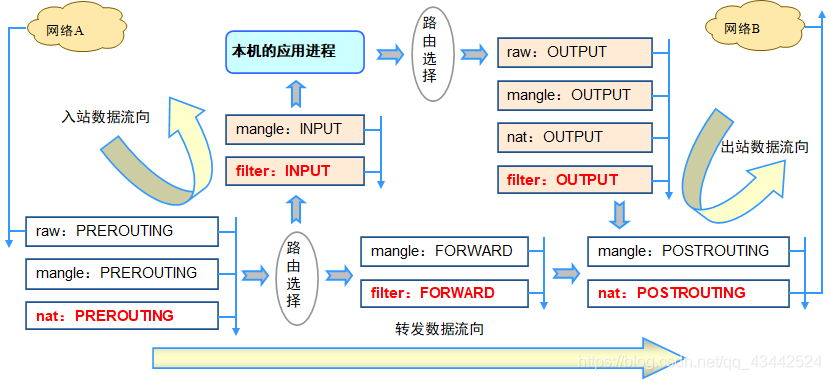
IPTABLES防火墙
IPTABLE的表、链结构
规则链 - 规则的作用:对数据包进行过滤或处理
- 链的作用:容纳各种防火墙规则
- 链的分类依据:处理数据包的不同时机
默认包括5种规则链
- INPUT:处理入站数据包
- OUTPUT:处理出站数据包
- FORWARD:处理转发数据包
- POSTROUTING链:在进行路由选择后处理数据包
- PREROUTING链:在进行路由选择前处理数据包
规则表
- 表的作用:容纳各种规则链
- 表的划分依据:防火墙规则的作用相似
默认包括4个规则表
- raw表:确定是否对该数据包进行状态跟踪
- mangle表:为数据包设置标记
- nat表:修改数据包中的源、目标IP地址或端口
- filter表:确定是否放行该数据包(过滤)
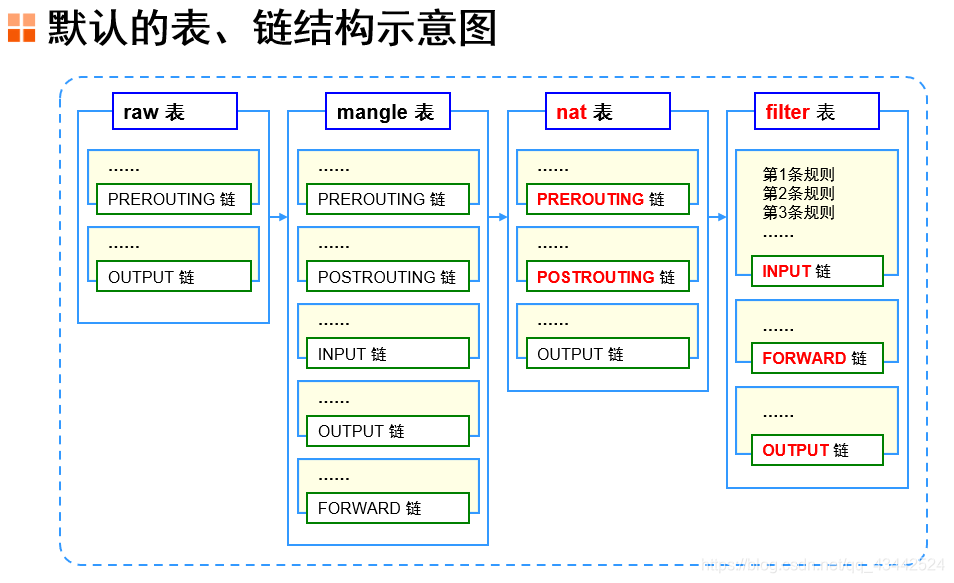
规则表之间的顺序 - raw -> mangle -> nat -> filter
规则链之间的顺序
- 入站:PREROUTING -> INPUT
- 出站:OUTPUT -> POSTROUTING
- 转发:PREROUTING -> FORWARD -> POSTROUTING
规则链内的匹配顺序
- 按顺序依次检查,匹配即停止(LOG策略例外)
- 若找不到相匹配的规则,则按该链的默认策略处理
语法构成
iptables [-t 表名] 选项 [链名] [条件] [-j 控制类型]
[root@localhost ~]# iptables -t filter -I INPUT -p icmp -j REJECT
几个注意事项
- 不指定表名时,默认指filter表
- 不指定链名时,默认指表内的所有链
- 除非设置链的默认策略,否则必须指定匹配条件
- 选项、链名、控制类型使用大写字母,其余均为小写
数据包的常见控制类型
- ACCEPT:允许通过
- DROP:直接丢弃,不给出任何回应
- REJECT:拒绝通过,必要时会给出提示
- LOG:记录日志信息,然后传给下一条规则继续匹配
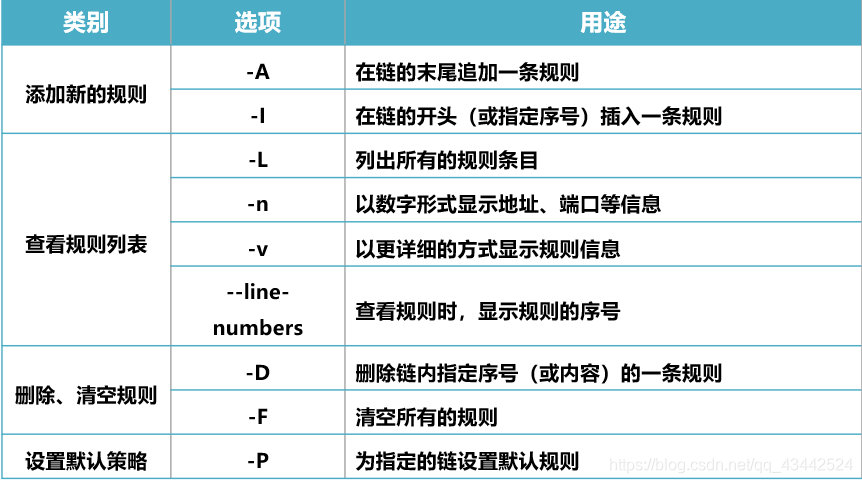
添加新的规则1
2-A:在链的末尾追加一条规则
-I:在链的开头(或指定序号)插入一条规则
1 | [root@localhost ~]# iptables -t filter -A INPUT -p tcp -j ACCEPT |
查看规则列表1
2
3
4-L:列出所有的规则条目
-n:以数字形式显示地址、端口等信息
-v:以更详细的方式显示规则信息
--line-numbers:查看规则时,显示规则的序号
1 | [root@localhost ~]# iptables -n -L INPUT |
删除、清空规则1
2-D:删除链内指定序号(或内容)的一条规则
-F:清空所有的规则
1 | [root@localhost ~]# iptables -D INPUT 3 |
具体设置静态IP可以查看我这篇文章:
Centos7下NAT设置静态ip
问题
设置静态以后发现 ==ping: www.baidu.com: Name or service not known==
但是ping网关192.168.233.2,DNS服务器8.8.8.8与114.114.114.114都能ping通
并且设置完静态显示正常 Xshell也可以正常连接1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25[root@localhost ~]# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:15:b8:04 brd ff:ff:ff:ff:ff:ff
inet 192.168.233.128/24 brd 192.168.233.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
[root@localhost ~]# ping 8.8.8.8
PING 8.8.8.8 (8.8.8.8) 56(84) bytes of data.
64 bytes from 8.8.8.8: icmp_seq=3 ttl=128 time=48.4 ms
64 bytes from 8.8.8.8: icmp_seq=9 ttl=128 time=47.0 ms
64 bytes from 8.8.8.8: icmp_seq=10 ttl=128 time=46.7 ms
^C
--- 8.8.8.8 ping statistics ---
10 packets transmitted, 3 received, 70% packet loss, time 9006ms
rtt min/avg/max/mdev = 46.738/47.412/48.467/0.776 ms
[root@localhost ~]# ping 114.114.114.114
PING 114.114.114.114 (114.114.114.114) 56(84) bytes of data.
64 bytes from 114.114.114.114: icmp_seq=1 ttl=128 time=26.7 ms
64 bytes from 114.114.114.114: icmp_seq=2 ttl=128 time=26.4 ms
64 bytes from 114.114.114.114: icmp_seq=3 ttl=128 time=24.9 ms
修改/etc/resolv.conf文件也无果1
2
3
4
5
6
7
8
9
10[root@localhost ~]# cat /etc/resolv.conf
# Generated by NetworkManager
nameserver 8.8.8.8
nameserver 114.114.114.114
nameserver 192.168.233.2
[root@localhost ~]# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.233.2 0.0.0.0 UG 100 0 0 ens33
192.168.233.0 0.0.0.0 255.255.255.0 U 100 0 0 ens33
解决
解决DNS解析错误问题无果后 尝试使用dhclient命令分配dhcp地址1
2
3
4
5
6
7
8
9
10
11
12
13
14[root@localhost ~]# dhclient
[root@localhost ~]# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:15:b8:04 brd ff:ff:ff:ff:ff:ff
inet 192.168.233.128/24 brd 192.168.233.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet 192.168.233.129/24 brd 192.168.233.255 scope global secondary dynamic ens33
valid_lft 1770sec preferred_lft 1770sec
可以发现运行完dhclient命令后出现了inet 192.168.233.129/24 brd 192.168.233.255 scope global secondary dynamic ens33 valid_lft 1770sec preferred_lft 1770sec
这一行代表网卡被分配了额外的dhcp地址 现在进行ping www.baidu.com1
2
3
4
5
6
7
8
9
10[root@localhost ~]# ping www.baidu.com
PING www.a.shifen.com (220.181.38.150) 56(84) bytes of data.
64 bytes from 220.181.38.150: icmp_seq=1 ttl=128 time=4.80 ms
64 bytes from 220.181.38.150: icmp_seq=2 ttl=128 time=5.43 ms
64 bytes from 220.181.38.150: icmp_seq=3 ttl=128 time=8.02 ms
64 bytes from 220.181.38.150: icmp_seq=4 ttl=128 time=5.12 ms
^C
--- www.a.shifen.com ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 3005ms
rtt min/avg/max/mdev = 4.809/5.849/8.026/1.276 ms
推测dns目前由dhcp到的192.168.233.129地址解析
在 docker 配置文件中设置
docker 1.12 版本之后, 建议在 docker 的 js 配置文件中配置, 路径为 /etc/docker/daemon.json 默认没有这个文件, 可以手动创建此文件, docker 启动时默认会读取此配置文件1
2
3{
"registry-mirrors": ["https://6y2639ye.mirror.aliyuncs.com"]
}
我这里配置的加速源
在一次误操作中 动了/usr/lib/systemd/system/docker.service下的文件 报错:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17[root@localhost ~]# systemctl status docker.service
● docker.service - Docker Application Container Engine
Loaded: loaded (/usr/lib/systemd/system/docker.service; enabled; vendor preset: disabled)
Active: failed (Result: start-limit) since 四 2020-05-14 10:19:16 CST; 25s ago
Docs: https://docs.docker.com
Process: 2493 ExecStart=/usr/bin/dockerd -H fd:// --containerd=/run/containerd/containerd.sock (code=exited, status=1/FAILURE)
Main PID: 2493 (code=exited, status=1/FAILURE)
5月 14 10:19:14 localhost.localdomain systemd[1]: Failed to start Docker Application Container Engine.
5月 14 10:19:14 localhost.localdomain systemd[1]: Unit docker.service entered failed state.
5月 14 10:19:14 localhost.localdomain systemd[1]: docker.service failed.
5月 14 10:19:16 localhost.localdomain systemd[1]: docker.service holdoff time over, scheduling restart.
5月 14 10:19:16 localhost.localdomain systemd[1]: Stopped Docker Application Container Engine.
5月 14 10:19:16 localhost.localdomain systemd[1]: start request repeated too quickly for docker.service
5月 14 10:19:16 localhost.localdomain systemd[1]: Failed to start Docker Application Container Engine.
5月 14 10:19:16 localhost.localdomain systemd[1]: Unit docker.service entered failed state.
5月 14 10:19:16 localhost.localdomain systemd[1]: docker.service failed.
解决
是因为 docker 的 socket 配置出现了冲突, 接下来查看 docker 的启动入口文件
1
2
3
4
5> vim /lib/systemd/system/docker.service # Ubuntu的路径; CentOS 的路径为: /usr/lib/systemd/system/docker.service
ExecStart=/usr/bin/dockerd -H fd://
修改为
ExecStart=/usr/bin/dockerd
从上面可以看出, 在 docker 的启动入口文件中配置了 host 相关的信息, 而在 docker 的配置文件中也配置了 host 的信息, 所以发生了冲突. 解决办法, 建议将 docker 启动入口文件中的 -H fd:// 删除, 再重启 docker 服务即可1
2[root@localhost ~]# systemctl daemon-reload
[root@localhost ~]# systemctl start docker
@[toc]
Python垃圾回收
引用计数器为主,标记清除和分代回收为辅+缓存机制
1. 引用计数器
1.1 环状双向链表 refchain
在Python程序中创建的任何对象都会放在refchain中
static PyObject refchain = {&refchain, &refchain}
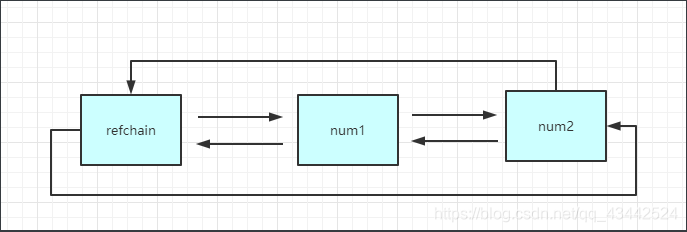
在Python程序中创建的任何对象都会放在refchain链表中
1 | str1 = "str" |
当进行上述操作时,Python内部会创建一些数据(上一个对象,下一个对象,类型,引用个数,元素个数)
include/object.h
1 |
|
2个结构体
- PyObject,此结构体中包含3个元素。
- _PyObject_HEAD_EXTRA,用于构造双向链表。
- ob_refcnt,引用计数器。
- ob_type,数据类型。
- PyVarObject,次结构体中包含4个元素(ob_base中包含3个元素)
- ob_base,PyObject结构体对象,即:包含PyObject结构体中的三个元素。
- ob_size,内部元素个数。
3个宏定义
- PyObject_HEAD,代指PyObject结构体。
- PyVarObject_HEAD,代指PyVarObject对象。
- _PyObject_HEAD_EXTRA,代指前后指针,用于构造双向队列。
Python中所有类型创建对象时,底层都是与PyObject和PyVarObject结构体实现,一般情况下由单个元素组成对象内部会使用PyObject结构体(float)、由多个元素组成的对象内部会使用PyVarObject结构体(str/int/list/dict/tuple/set/自定义类),因为由多个元素组成的话是需要为其维护一个 ob_size(内部元素个数)。
PyObject:float
PyVarObject:list、dict、tuple、set、int、str、bool
因为Python中的int是不限制长度的,所以底层实现是用的str,所以int也属于PyVarObject阵营。Python中的bool实际上是0和1,所以也是int,也属于PyVarObject阵营。
1.2 类型封装结构体
1 | // float类型 |
1 | data = 1.11 |
1.3 引用计数器
1 | v1 = 1.11 |
当python程序运行时,会根据数据类型的不同找到对应的结构体,根据结构体中的字段来进行创建相关的数据,然后将对象添加到refchain双线链表中。
每个对象中有ob_refcnt引用计数器,值默认为1,当有其他变量引用对象时,引用计数器就会发生变化。
1 | a = 1 |
1 | a = 1 |
1 | # 创建对象并初始化引用计数器为1 |
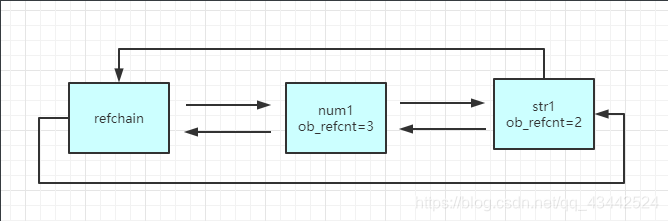
1.4 循环引用的问题
1 | list1 = [1,2,3] |
list1与list2相互引用,如果不存在其他对象对它们的引用,list1与list2的引用计数也仍然为1,所占用的内存永远无法被回收,这将是致命的。
对于如今的强大硬件,缺点1尚可接受,但是循环引用导致内存泄露,注定python还将引入新的回收机制。
2. 标记清除
目的:为了解决引用计数器循环引用的不足
实现:在Python的底层再维护一个链表,链表中专门放可能存在循环引用的对象(list/tuple/dict/set)
![\[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Y2sWHo9q-1589031264635)(../../Images/image-20200509205236478.png)\]](https://img-blog.csdnimg.cn/20200509213523566.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQzNDQyNTI0,size_16,color_FFFFFF,t_70)
在Python内部某种情况触发, 会去扫描可能存在循环应用的链表中的每个元素, 检查是否有循环引用, 如果有则让双方的引用计数器-1; 如果是0则进行垃圾回收
问题:
- 什么时候扫描
- 可能存在循环引用的链表扫描代价大,每次扫描时间久
3. 分代回收
将可能存在循环应用的对象维护成3个链表:
- 0代:0代中对象的个数达到700个扫描一次
- 1代:0代扫描10次,则1代扫描一次
- 2代:1代扫描10次,则2代扫描一次
4. 小结
在Python中维护了一个refchain的双向环状链表, 这个链表中存储程序创建的所有对象, 每种类型的对象中都有一个ob_refcnt引用计数器的值, 引用个数+1, -1 , 最后当引用计数器变成0时会进行垃圾回收(对象销毁, 从refchain中移除)
但是. 在Python中对于那些可以有多个元素组成的对象可能会存在循环引用的问题, 为了解决这个问题Python引入了标记清除和分带回收, 在其内部维护了4个链表
- refchain
- 0代
- 1代
- 2代
在源码内部当达到各自的阈值时, 就会触发扫描链表进行标记清除的动作(有循环则各自-1)
Python缓存
1. 池
为了避免重复创建和销毁一些常见对象, Python建立了维护池
1 | # 启动解释器时, python内部帮我们创建: -5,-4...257 |
2. free_list
当一个对象的引用计数器为0时, 按理说应该回收, 但是内部不会直接回收, 而是将对象添加到free_list链表中当缓存。以后再去创建对象时,不再重新开辟内存,而是直接使用free_list
1 | v1 = 1.11 # 开辟内存, 内存存储结构体中定义那几个值, 并存到refchain中 |
float类型,维护的free_list链表最多可缓存100个float对象。
1
2
3
4
5
6v1 = 3.14 # 开辟内存来存储float对象,并将对象添加到refchain链表。
print( id(v1) ) # 内存地址:4436033488
del v1 # 引用计数器-1,如果为0则在rechain链表中移除,不销毁对象,而是将对象添加到float的free_list.
v2 = 9.999 # 优先去free_list中获取对象,并重置为9.999,如果free_list为空才重新开辟内存。
print( id(v2) ) # 内存地址:4436033488
# 注意:引用计数器为0时,会先判断free_list中缓存个数是否满了,未满则将对象缓存,已满则直接将对象销毁。int类型,不是基于free_list,而是维护一个small_ints链表保存常见数据(小数据池),小数据池范围:
-5 <= value < 257。即:重复使用这个范围的整数时,不会重新开辟内存。1
2
3
4
5v1 = 38 # 去小数据池small_ints中获取38整数对象,将对象添加到refchain并让引用计数器+1。
print( id(v1)) #内存地址:4514343712
v2 = 38 # 去小数据池small_ints中获取38整数对象,将refchain中的对象的引用计数器+1。
print( id(v2) ) #内存地址:4514343712
# 注意:在解释器启动时候-5~256就已经被加入到small_ints链表中且引用计数器初始化为1,代码中使用的值时直接去small_ints中拿来用并将引用计数器+1即可。另外,small_ints中的数据引用计数器永远不会为0(初始化时就设置为1了),所以也不会被销毁。str类型,维护
unicode_latin1[256]链表,内部将所有的ascii字符缓存起来,以后使用时就不再反复创建。1
2
3
4
5
6
7v1 = "A"
print( id(v1) ) # 输出:4517720496
del v1 v2 = "A"
print( id(v1) ) # 输出:4517720496 # 除此之外,Python内部还对字符串做了驻留机制,针对那么只含有字母、数字、下划线的字符串(见源码Objects/codeobject.c),如果内存中已存在则不会重新在创建而是使用原来的地址里(不会像free_list那样一直在内存存活,只有内存中有才能被重复利用)。
v1 = "wupeiqi"
v2 = "wupeiqi"
print(id(v1) == id(v2)) # 输出:Truelist类型,维护的free_list数组最多可缓存80个list对象。
1
2
3
4v1 = [11,22,33]
print( id(v1) ) # 输出:4517628816
del v1 v2 = ["武","沛齐"]
print( id(v2) ) # 输出:4517628816tuple类型,维护一个free_list数组且数组容量20,数组中元素可以是链表且每个链表最多可以容纳2000个元组对象。元组的free_list数组在存储数据时,是按照元组可以容纳的个数为索引找到free_list数组中对应的链表,并添加到链表中。
1
2
3
4
5v1 = (1,2)
print( id(v1) )
del v1 # 因元组的数量为2,所以会把这个对象缓存到free_list[2]的链表中。
v2 = ("武沛齐","Alex") # 不会重新开辟内存,而是去free_list[2]对应的链表中拿到一个对象来使用。
print( id(v2) )dict类型,维护的free_list数组最多可缓存80个dict对象。
1
2
3
4v1 = {"k1":123}
print( id(v1) ) # 输出:4515998128
del v1 v2 = {"name":"武沛齐","age":18,"gender":"男"}
print( id(v1) ) # 输出:4515998128
这个老师讲的通俗易懂, 非常棒, 更多详细的解释:https://pythonav.com/wiki/detail/6/88/
参考资料:
https://www.bilibili.com/video/BV1Ei4y1b7mo?p=2
https://my.oschina.net/hebianxizao/blog/57367
https://www.cnblogs.com/wupeiqi/articles/11507404.html
在使用git push时报出如下的错误:1
2
3
4
5
6$ git push -u origin master
fatal: HttpRequestException encountered.
发送请求时出错。
fatal: HttpRequestException encountered.
发送请求时出错。
Username for 'https://github.com':
之前时不需要输入的,现在需要输入了,原因是git更新了一个证书,我们本地需要再更新以下:
https://github.com/microsoft/Git-Credential-Manager-for-Windows/releases
进去后点击下载安装 GCMW最新版即可:
NFS介绍
NFS 是Network File System的缩写,即网络文件系统。一种使用于分散式文件系统的协定,由Sun公司开发,于1984年向外公布。功能是通过网络让不同的机器、不同的操作系统能够彼此分享个别的数据,让应用程序在客户端通过网络访问位于服务器磁盘中的数据,是在类Unix系统间实现磁盘文件共享的一种方法。
NFS 的基本原则是“容许不同的客户端及服务端通过一组RPC分享相同的文件系统”,它是独立于操作系统,容许不同硬件及操作系统的系统共同进行文件的分享。
NFS在文件传送或信息传送过程中依赖于RPC协议。RPC,远程过程调用 (Remote Procedure Call) 是能使客户端执行其他系统中程序的一种机制。NFS本身是没有提供信息传输的协议和功能的,但NFS却能让我们通过网络进行资料的分享,这是因为NFS使用了一些其它的传输协议。而这些传输协议用到这个RPC功能的。可以说NFS本身就是使用RPC的一个程序。或者说NFS也是一个RPC SERVER。所以只要用到NFS的地方都要启动RPC服务,不论是NFS SERVER或者NFS CLIENT。这样SERVER和CLIENT才能通过RPC来实现PROGRAM PORT的对应。可以这么理解RPC和NFS的关系:NFS是一个文件系统,而RPC是负责负责信息的传输。
什么是RPC
由于NFS支持的功能相当多,而不同的功能都会使用不同的程序来启动,每启动一个功能就会启用一些端口来传输数据,因此,NFS的功能所对应的端口才无法固定,而是随机取用一些未使用的端口来作为传输之用,其中centos5.x随机端口为小于1024的,而centos6.x随机端口都是较大的。
因为端口不固定,这样一来就会造成客户端与NFS服务器端的通讯障碍,由于NFS客户端必须要知道NFS服务器端的数据传输端口才能进行通信交互数据。
解决以上问题,我们需要RPC服务来帮忙,NFS的RPC服务主要的功能是记录每个NFS功能所对应的端口号,并且在NFS客户端请求时将该端口和功能对应的信息传递给请求数据的NFS客户端,从而可以确保客户端连接正确的NFS端口上去,达到实现数据传输交互数据目的。RPC相当于NFS服务的中介。
如图所示:NFS工作流程简图
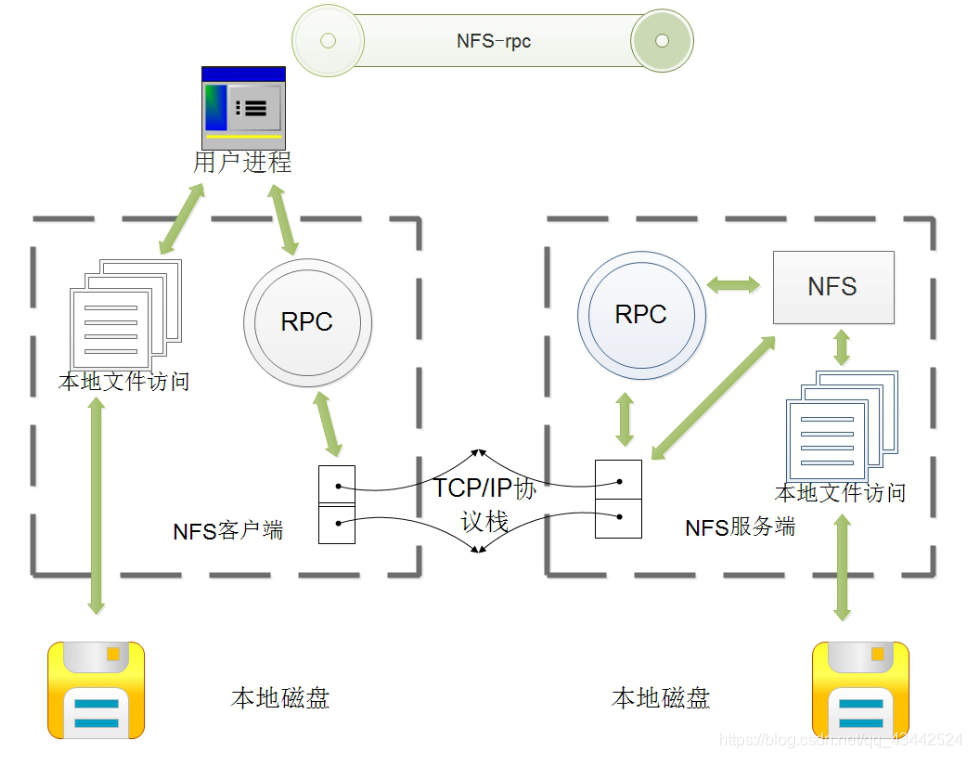
大致如以下几点:
1、首先用户访问网站程序,由程序在NFS客户端上发出NFS文件存取功能的询问请求,这时NFS客户端(即执行程序的服务器)RPC服务(portmap或rpcbind服务)就会通过网络向NFS服务端的RPC服务(portmap或rpcbind)的111端口发出NFS文件存取功能的询问请求。
2、NFS服务器端的RPC服务(即portmap或rpcbind)找到对应的已注册的NFS daemon端口后,通知NFS客户端的RPC服务(即portmap或rpcbind服务)
3、此时NFS客户端就可以获取到正确的端口,然后就直接与NFS daemon联机存取数据了。
4、NFS客户端把数据存取成功后,返回给当前访问程序,告知用户存取结果,作为网站用户,我们就完成了一次存取操作。 由于NFS的各项功能都需要想RPC服务注册,所以RPC服务才能获取到NFS服务的各项功能对应的端口、PID、NFS在主机所监听的IP等,NFS客户端才能够通过向RPC服务询问才找到正确的端口。也就是说,NFS需要有RPC服务的协助才能成功对外提供服务。由上面的描述,我们不难推出:无论是NFS客户端还是NFS服务器端,当要使用NFS时,都需要首先启动RPC服务,然后在启动NFS服务,客户端可以不启动NFS服务。
安装配置NFS服务器
使用docker容器配置NFS服务器
1) 启动centos容器并进入
docker run -d –privileged centos:v1 /usr/sbin/init
2) 在centos容器中使用yum方式安装nfs-utilsyum install nfs-utils
3) 保存容器为镜像
#docker commit 容器ID nfs
4) 启动容器nfs,设定地址为172.18.0.120
#docker run -d –privileged –net cluster –ip 172.18.0.120 –name nfs nfs /usr/sbin/init
5) 启动nfs服务,查看监听端口systemctl start nfs-server
7) 新建共享目录/var/www/share,设置权限为777
8) 编辑/etc/exports文件/var/www/share 172.18.0.*(rw,sync)
9) 导出nfs共享目录exportfs -rv
10) 查看nfs上的共享目录
#showmount -e IP地址1
2
3[root@c90e05748250 /]# showmount -e 172.18.0.1
Export list for 172.18.0.1:
/var/www/share 172.18.0.*
使用宿主机配置NFS服务器
1) yum install nfs-utils //在宿主机安装nfs
2) 查看nfs配置文件1
2more /etc/nfs.onf
more /etc/nfsmount.conf
3) 启动nfs服务,查看监听端口
systemctl start nfs-server
4) 新建共享目录/var/www/share,设置权限为777
5) 编辑/etc/exports文件/var/www/share 172.18.0.*(rw,sync)
6) 导出nfs共享目录#exportfs -rv
7) 查看nfs上的共享目录
#showmount -e IP地址1
2
3showmount -e 172.18.0.1
Export list for 172.18.0.1:
/var/www/share 172.18.0.*
启用APP1和APP2两个容器,挂载共享目录
1) 启动容器APP1,设定地址为172.18.0.111
docker run -d –privileged –net cluster –ip 172.18.0.111 –name APP1 php-apache /usr/sbin/init
2) 启动容器APP2,设定地址为172.18.0.112
docker run -d –privileged –net cluster –ip 172.18.0.112 –name APP2 php-apache /usr/sbin/init
3) yum install nfs-utils //进入容器并安装nfs
4) #showmount -e 172.18.0.1 //在APP1查看nfs上的共享目录1
2
3showmount -e 172.18.0.1
Export list for 172.18.0.1:
/var/www/share 172.18.0.*
5) 共享目录挂在到本地目录1
2mkdir /var/www/share
mount 172.18.0.1:/var/www/share /var/www/share
6) 在APP1的/var/www/share上读写文件,在nfs上查看
7) APP2按以上步骤配置
配置nginx1、APP1实现动静分离
在APP1上编写PHP脚本,上传资源文件
1) vim /var/www/index.php //在APP1上编辑php文件1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
function serverIp(){ //获取服务器IP地址
if(isset($_SERVER)){
if($_SERVER['SERVER_ADDR']){
$server_ip=$_SERVER['SERVER_ADDR'];
}else{
$server_ip=$_SERVER['LOCAL_ADDR'];
}
}else{
$server_ip = getenv('SERVER_ADDR');
}
return $server_ip;
}
<!doctype html>
<html>
<head>
<meta charset="utf-8">
<title>动静分离测试</title>
<link rel="stylesheet" type="text/css" href="share/banner.css">
<script type="text/javascript" src="share/jquery-1.7.2.min.js"></script>
</head>
<body>
<div class="banner">
<ul>
<li><img src="share/banner_02.jpg" /></li>
<li><img src="share/banner_01.gif" /></li>
</ul>
</div>
<div class="main_list">
<ul>
<li><a href="#">动静分离测试...</a></li>
<li><a href="#">动静分离测试...</a></li>
</ul>
</div>
<span> echo serverIp(); </span>
</body>
</html>
4) 把图片资源文件上传到APP1服务器的 /var/www/share目录
5) 在宿主机nfs服务器的 /var/www/share目录中检查文件是否存在
6) 在宿主机使用curl访问http://172.18.0.111/index.php
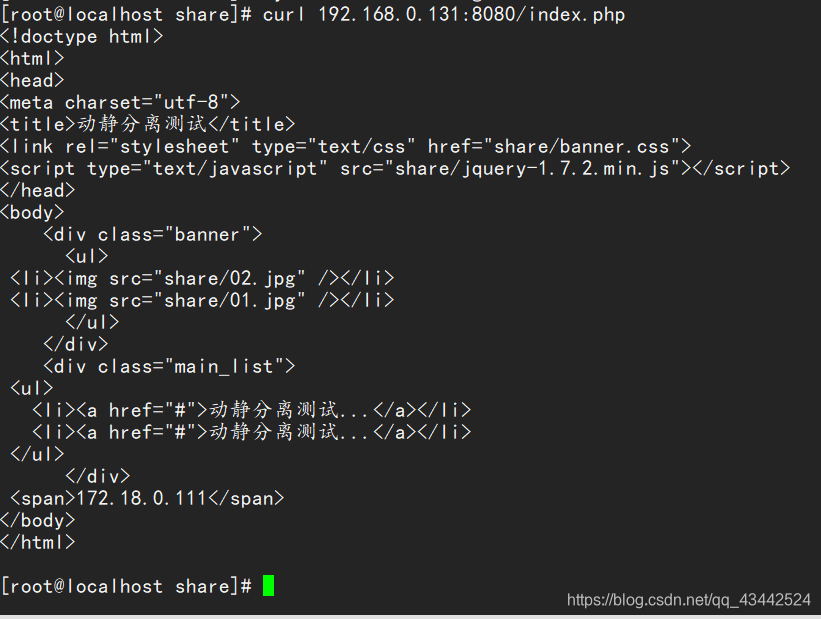
配置nginx反向代理,访问APP1
1) 启动容器nginx1,设定地址为172.18.0.11,把80端口映射到宿主机8080
docker run -d –privileged –net cluster –ip 172.18.0.11 -p 8080:80 –name nginx1 nginx-keep /usr/sbin/init
2) 在nginx1上编辑/etc/nginx/nginx.conf,重启nginx服务1
2
3
4
5
6server {
listen 80;
server_name localhost;
location / {
proxy_pass http://172.18.0.111;
}
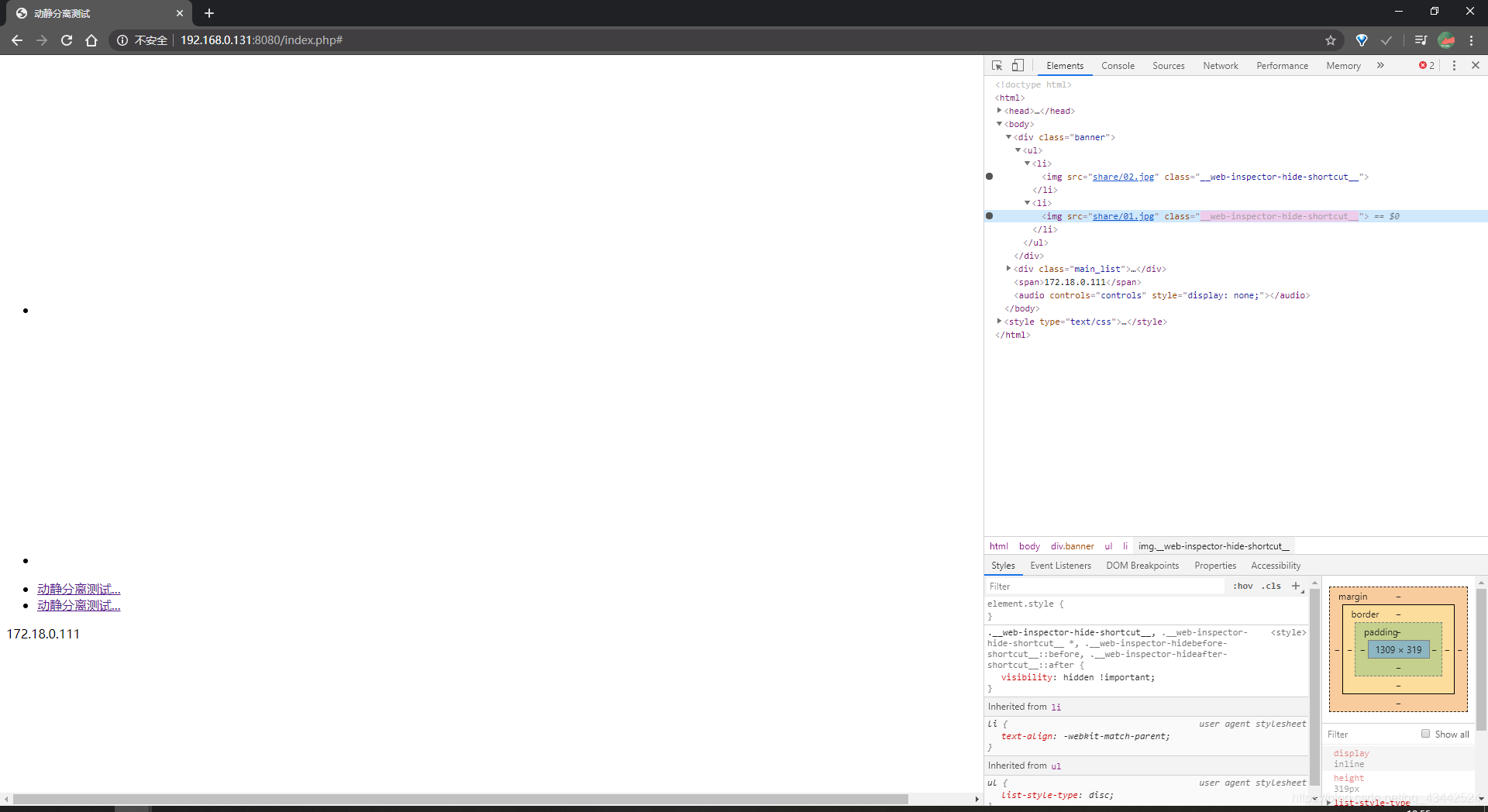
3) 在主机使用浏览器访问http://192.168.*.100/index.php
这里肯定显示不了图片 因为网站的根目录为/var/www/html而share目录在/var/www下
配置nginx反向代理,宿主机nginx,支持动静分离
1) 在nfs宿主机编辑/etc/nginx/conf.d/ default.conf,启用nginx服务1
2
3
4
5
6
7
8server {
listen 80;
server_name file.test.com;
location / {
root /var/www;
index index.html index.htm;
}
}
2) 在nginx1上编辑/etc/nginx/nginx.conf,重启nginx服务1
2
3
4
5
6
7
8
9
10server {
listen 80;
server_name localhost;
location / {
proxy_pass http://172.18.0.111;
}
location /share {
proxy_pass http://172.18.0.1/share;
}
}
3) 在主机使用浏览器访问http://192.168.*.100/index.php
配置nginx1、APP1、APP2、宿主机nfs和nginx,支持负载均衡动静分离
1) 仿照步骤1,在APP2上编写PHP脚本,上传资源文件
3) 在nginx1上编辑/etc/nginx/nginx.conf,重启nginx服务1
2
3
4
5
6
7
8
9
10
11
12
13
14server {
listen 80;
server_name localhost;
location / {
proxy_pass http://APP;
}
location /share {
proxy_pass http://172.18.0.1/share;
}
upstream APP {
server 172.18.0.111;
server 172.18.0.112;
}
}
4) 在主机使用浏览器访问http://192.168.*.100/index.php
Docker三剑客
为了把容器化技术的优点发挥到极致,docker公司先后推出了三大技术
- docker-machine
- docker-compose
- docker-swarm
它们可以说是几乎实现了容器化技术中所有可能需要的底层技术手段。
- docker-machine - 提供容器服务
- docker-compose - 提供脚本执行服务,不用在像以前把容器的启动命令写的非常的长,用compose编写脚本就能简化容器的启动
- 几条简单指令就可以创建一个docker集群,最终实现分布式的服务
Docker 三剑客之 Machine
Docker Machine 是 Docker 官方三剑客项目之一 ,负责使用 Docker 容器的第一步 :在多
种平台上快速安装和维护 Docker 运行环境 。 它支持多种平 台 ,让用户可以在很短时间内在
本地或云环境中搭建一套 Docker 主机集群。
Machine 简介
Machine 项目是 Docker 官方的开源项目 ,负责实现对 Docker 运行环境进行安装和管理,特别在管理多个 Docker 环境时,使用 Machine 要比手动管理高效得多。
Machine 的定位是“在本地或者云环境中创建 Docker 主机”
其代码在https://github.com/docker/machine 上开源,遵循 Apache-2.0 许可
Machine 项目主要由 Go 语言编写,用户可以在本地任意指定由 Machine 管理的 Docker主机,并对其进行操作。
其基本功能包括:
- 在指定节点或平台上安装 Docker 引擎,配置其为可使用的 Docker 环境;
- 集中管理(包括启动 、查看等)所安装 的Docker 环境。
Machine 连接不同类型的操作平台是通过对应驱动来实现 的,目前已经集成了包括AWS 、 IBM 、 Google ,以及 OpenStack 、 VirtualBox 、 vSphere 等多种云平台的支持。
安装
在 Linux 平台上的安装十分简单,推荐从官方 Release 库https://github.corn/docker/machine/releases 直接下载编译好的二进制文件即可
在 Linux 64 位系统上直接下载对应的二进制包1
2
3
4
5
6$ sudo curl -L https://github.com/docker/machine/releases/download/v0.13.0/docker-machine- ' uname -s'-'uname -m ' > docker-machine
$ sudo mv docker-machine /usr/ local/bin/docker-machine
$ sudo chmod +x /usr/local/bin/docker-machine
安装完成后,查看版本信息,验证运行正常:
$ docker-machine -v
docker-machine version 0.13.0
当要对多个 Docker 主机环境进行安装、配置和管理时,采用 Docker Machine 的方式将远比手动方式
快捷。 不仅提高了操作速度,更通过批量统一的管理减少了出错的可能。 尤其在大规模集群和云平台环境中推荐使用
Docker 三剑客之 Compose
编排( Orchestration )功能,是复杂系统是否具有灵活可操作性的关键。 特别在 Docker应用场景中,编排意味着用户可以灵活地对各种容器资源实现定义和管理。
Compose 作为 Docker 官方编排工具,其重要性不言而喻,它可以让用户通过编写一个简单的模板文件,快速地创建和管理基于 Docker 容器的应用集群。
Compose 简介
Compose 项目是 Docker 官方的开源项目,负责实现对基于 Docker 容器的多应用服务的快速编排。 从功能上看,跟 Open Stack 中的 Heat 十分类似。 其代码目前在 https://github .com/docker/compose 巳上开源 。
Compose 定位是“定义和运行多个 Docker 容器的应用”,其前身是开源项目Fig ,目前仍然兼容 Fig 格式的模板文件。
在日常工作中,经常会碰到需要多个容器相互配合来完成某项任务的情况。 例如要实现一个 Web 项目,除了 Web 服务容器本身,往往还需要再加上后端的数据库服务容器,甚至还包括前端的负载均衡容器等。
Compose 恰好满足了这样的需求。 它允许用户通过一个单独的 docker-compose.yml模板文件( YAML 格式)来定义一组相关联的应用容器为一个服务樵( stack )
Compose 中有几个重要的概念:
任务( task ) : 一个容器被称为一个任务。 任务拥有独一无二的 ID ,在同一个服务中的多个任务序号依次递增 。
服务( service ):某个相同应用镜像的容器副本集合,一个服务可以横向扩展为多个容器实例 。
服务枝 ( stack ) :由 多个服务组成 ,相互配合完成特定业务 , 如 Web 应用服务、数据
库服务共同构成 Web 服务钱 ,一般由一个 docker-cornpose.yml 文件定义。
Compose 的默认管理对象是服务钱,通过子命令对栈中的多个服务进行便捷的生命周期管理。
Compose 项目由 Python 编写 ,实现上调用了 Docker 服务提供的 API 来对容器进行管理。
因此,只要所操作的平台支持 Docker API,就可以在其上利用 Compose 来进行编排管理。
Compose安装
二进制包安装
这些发布的二进制包可以在https://github.com/docker/compose/releases 页面找到
将这些二进制文件下载后直接放到执行路径下,并添加执行权限即可。1
2
3
4
5
6
7
8
9$ sudo curl -L https : //github.com/docker/compose/releases/download/1.19.0/docker-compose- ’ uname -s ’- ’ uname -m’ > / usr/ local / bin/ docker-compose
$ sudo chmod a+x /usr/local/bin/docker-cornpose
可以使用 docker-compose version 命令来查看版本信息,以测试是否安装成功:
$ docker-compose version
docker compose version 1.19.0
docker-py version : 2.7.0
CPython version : 2.7.12
OpenSSL version : OpenSSL l.0.2g
在 Docker 三剑客中, Compose 掌管运行时的编排能力,位置十分关键。 使用 Compose模板文件,用户可以编写包括若干服务的一个模板文件快速启动服务栈;如果分发给他人,也可快速创建一套相同的服务栈。
Docker 三剑客之 Swarm
Docker Swarm 是 Docker 官方三剑客项目之一,提供 Docker 容器集群服务,是 Docker官方对容器云生态进行支持的核心方案。 使用它,用户可以将多个 Docker 主机抽象为大规模的虚拟 Docker 服务,快速打造一套容器云平台
Swarm 简介
Docker Swarm 是 Docker 公司推出的官方容器集群平台 , 基于 Go 语言实现,代码开源在 https:// github.com/ docker/swarm
目前,包括 Rackspace 等平台都采用了 Swarm ,用户也很容易在 AWS 等公有云平台使用 Swarm 。
Swarm 的前身是 Beam 项目和 libswarm 项目,首个正式版本( Swarm Vl )在 2014 年 12 月初发布 。 为了提高可扩展性, 2016 年 2 月对架构进行重新设计,推出了 V2 版本,支持超过 lK 个节点 。最新的 Docker Engine ( 1.12 后)已经集成SwarmKit 内嵌了对 Swarm 模式的支持。
作为容器集群管理器, Swarm 最大的优势之一就是原生支持 Docker API ,给用户使用带来极大的便利 。 各种基于标准 A凹的工具比如 Compose 、 Docker SDK 、各种管理软件, 甚至Docker 本身等都可以很容易的与 Swarm 进行集成。 这大大方便了用户将原先基于单节点的系统移植到 Swarm 上。 同时 Swarm 内置了对 Docker 网络插件的支持,用户可以很容易地部署跨主机的容器集群服务。
Swarm 也采用了典型的“主从”结构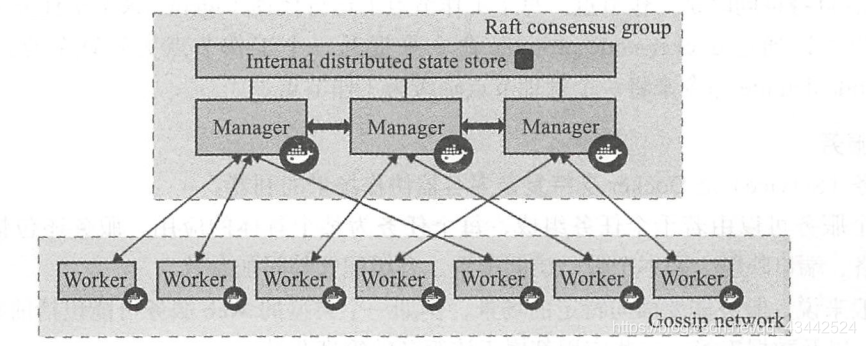
通过 Raft 协议来在多个管理节点( Manager )中实现共识。 工作节点( Worker )上运行 agent 接受管理节点的统一管理和任
务分配。 用户提交服务请求只需要发给管理节点即可,管理节点会按照调度策略在集群中分配节点来运行服务相关的任务
在 Swarm V2 中,集群中会自动通过 Raft 协议分布式选举出 Manager 节点,无须额外的发现服务支持,避免了单点瓶颈。 同时, V2 中内置了基于 DNS 的负载均衡和对外部负载均衡机制的集成支持。
Swarm 基本概念
Swarm 在 Docker 基础上扩展了支持多节点的能力,同时兼容了大部分的 Docker 操作。Swarm 中以集群为单位进行管理,支持服务层面的操作。
1. Swarm 集群
Swarm 集群( Cluster )为一组被统一管理起来的 Docker 主机。 集群是 Swarm 所管理的对象。 这些主机通过 Docker 引擎的 Swarm 模式相互沟通,其中部分主机可能作为管理节点(manager)响应外部的管理请求,其他主机作为工作节点( worker )来实际运行 Docker 容器。当然,同一个主机也可以即作为管理节点,同时作为工作节点 。
当用户使用 Swarm 集群时,首先定义一个服务(指定状态、复制个数、网络、存储 、 暴露端- 等),然后通过管理节点发出启动服务的指令,管理节点随后会按照指定的服务规则进行调度,在集群中启动起来整个服务,并确保它正常运行。
2. 节点
节点(Node )是 Swarm 集群的最小资源单位。 每个节点实际上都是一台 Docker 主机。
Swarm 集群中节点分为两种:
- 管理节点( manager node ): 负责响应外部对集群的操作请求,并维持集群中资源,分发任务给工作节点 。 同时,多个管理节点之间通过 Raft 协议构成共识。 一般推荐每个集群设置 5 个或 7 个管理节点;
- 工作节点( worker node ):负责执行管理节点安排的具体任务。 默认情况下,管理节点自身也同时是工作节点 。 每个工作节点上运行代理( agent )来汇报任务完成情况。用户可以通过 docker node promote 命令来提升一个工作节点为管理节点;或者通过docker node demote 命令来将一个管理节点降级为工作节点。
3. 服务
服务( Service)是 Docker 支持复杂多容器协作场景的利器。一个服务可以由若干个任务组成,每个任务为某个具体的应用。 服务还包括对应的存储 、 网络 、 端- 映射、副本个数 、 访问配置 、 升级配置等附加参数。一般来说,服务需要面向特定的场景,例如一个典型的 Web 服务可能包括前端应用 、 后
端应用,以及数据库等。 这些应用都属于该服务的管理范畴。
Swarm 集群中服务类型也分为两种(可以通过-mode 指定) :
- 复制服务( replicated services )模式 : 默认模式,每个任务在集群中会存在若干副本,
这些副本会被管理节点按照调度策略分发到集群中的工作节点上。 此模式下可以使
用-replicas 参数设置副本数量 ; - 全局服务( global services )模式 : 调度器将在每个可用节点都执行一个相同的任务。
该模式适合运行节点的检查,如监控应用等。4. 任务
任务是 Swarm 集群中最小的调度单位,即一个指定的应用容器。 例如仅仅运行前端业务的前端容器。 任务从生命周期上将可能处于创建( NEW ) 、 等待( PENDING ) 、 分配( ASSIGNED ) 、 接受( ACCEPTED ) 、 准备( PREPARING )、开始( STARTING ) 、 运行 (RUNING) 、 完成(COMPLETE )、失败(FAILED ) 、 关闭(SHUTDOWN) 、 拒绝(PEJECTED ) 、孤立( ORPHANED )等不同状态 。
Swarm 集群中的管理节点会按照调度要求将任务分配到工作节点上。 例如指定副本为 2时,可能会被分配到两个不同的工作节点上。一旦当某个任务被分配到一个工作节点,将无法被转移到另外的工作节点,即 Swarm 中的任务不支持迁移。
5 . 服务的外部访问
Swarm 集群中的服务要被集群外部访问,必须要能允许任务的响应端口映射出来。Swarm 中支持入口负载均衡(ingress load balancing )的映射模式。 该模式下,每个服务都会被分配一个公开端口( PublishedPort ),该端口在集群中任意节点上都可以访问到,并被保留给该服务。
当有请求发送到任意节点的公开端- 时,该节点若并没有实际执行服务相关的容器,则会通过路由机制将请求转发给实际执行了服务容器的工作节点 。
通过使用 Swarm ,用户可以将若干 Docker 主机节点组成的集群当作一个大的虚拟 Docker 主机使用 。 并且,原先基于单机的Docker 应用,可以无缝地迁移到 Swarm 上来。 通过使用服务, Swarm 集群可以支持多个应用构建的复杂业务,并很容易对其进行升级等操作 。
在生产环境中, Swarm 的管理节点要考虑高可用性和安全保护,一方面多个管理节点应该分配到不同的容灾区域,另一方面服务节点应该配合数字证书等手段限制访问 。Swarm 功能已 经被无缝嵌入Docker 1.12+版本中,用户今后可 以 直接使用 Docker命令来完成相关功能的配置,对 Swarm 集群的管理更加简便。
]]>Prometheus介绍
随着容器技术的迅速发展,Kubernetes 已然成为大家追捧的容器集群管理系统。Prometheus 作为生态圈 Cloud Native Computing Foundation(简称:CNCF)中的重要一员,其活跃度仅次于 Kubernetes, 现已广泛用于 Kubernetes 集群的监控系统中。
本文将简要介绍 Prometheus 的组成和相关概念,并实例演示 Prometheus 的安装,配置及使用。
Prometheus的特点:
- 多维度数据模型。
- 灵活的查询语言。
- 不依赖分布式存储,单个服务器节点是自主的。
- 通过基于HTTP的pull方式采集时序数据。
- 可以通过中间网关进行时序列数据推送。
- 通过服务发现或者静态配置来发现目标服务对象。
- 支持多种多样的图表和界面展示,比如Grafana等
官方架构图
官方网站:https://prometheus.io/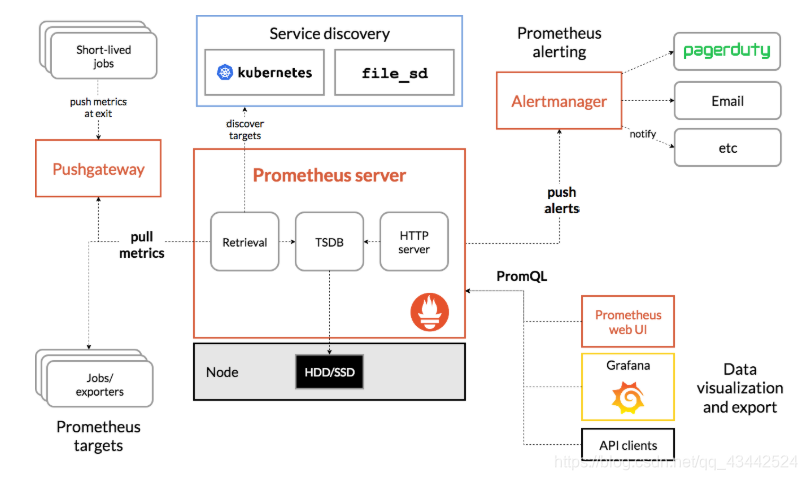
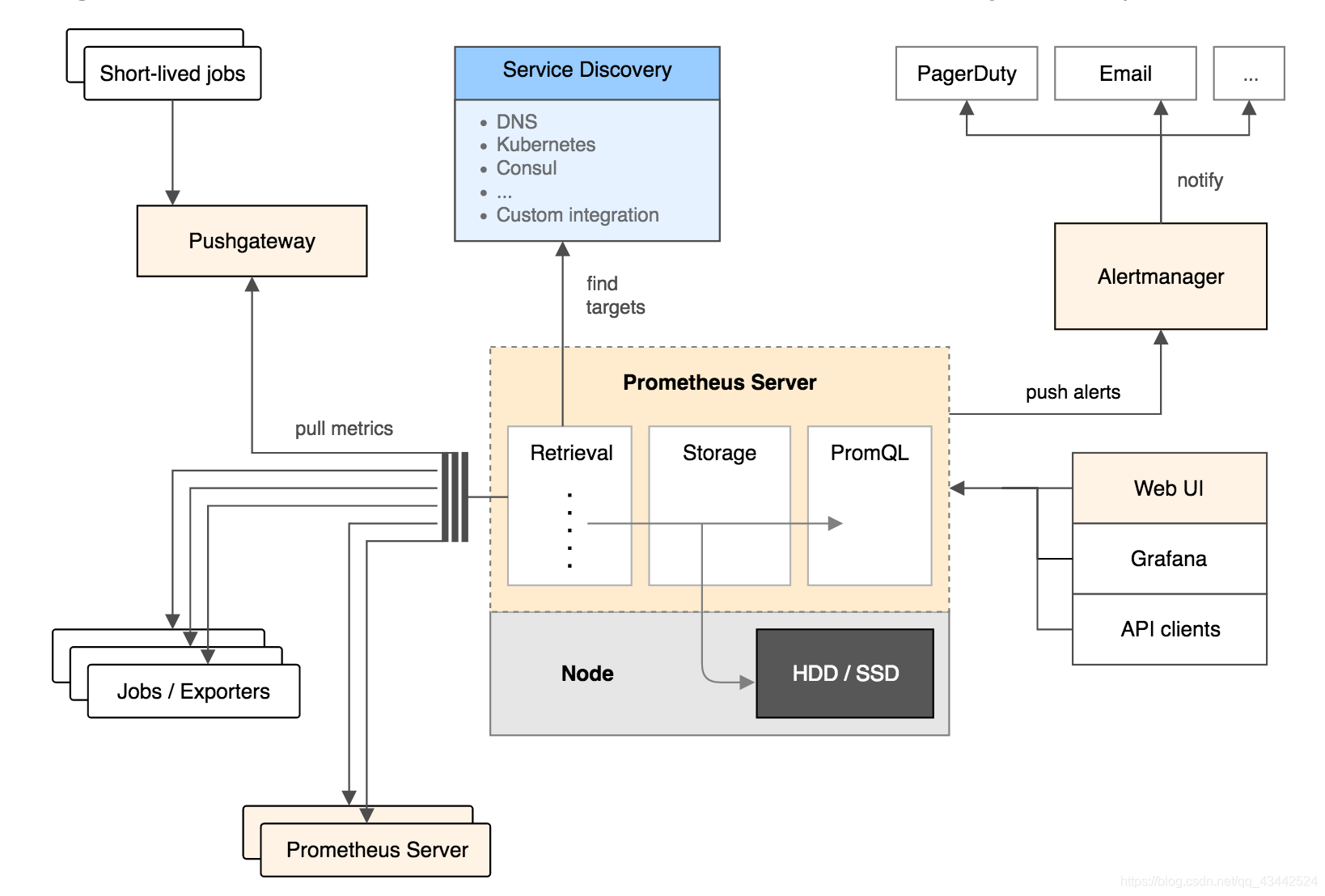
Prometheus 生态圈中包含了多个组件,其中许多组件是可选的:
- Prometheus Server: 用于收集和存储时间序列数据。
- Client Library: 客户端库,为需要监控的服务生成相应的 metrics 并暴露给 Prometheus server。当 Prometheus server 来 pull 时,直接返回实时状态的 metrics。
- Push Gateway: 主要用于短期的 jobs。由于这类 jobs 存在时间较短,可能在 Prometheus 来 pull 之前就消失了。为此,这次 jobs 可以直接向 Prometheus server 端推送它们的 metrics。这种方式主要用于服务层面的 metrics,对于机器层面的 metrices,需要使用 node exporter。
- Exporters: 用于暴露已有的第三方服务的 metrics 给 Prometheus。
- Alertmanager: 从 Prometheus server 端接收到 alerts 后,会进行去除重复数据,分组,并路由到对收的接受方式,发出报警。常见的接收方式有:电子邮件,pagerduty,OpsGenie, webhook 等一些其他的工具。
Prometheus的基本原理
Prometheus的基本原理是通过HTTP协议周期性抓取被监控组件的状态,任意组件只要提供对应的HTTP接口就可以接入监控。不需要任何SDK或者其他的集成过程。这样做非常适合做虚拟化环境监控系统,比如VM、Docker、Kubernetes等。输出被监控组件信息的HTTP接口被叫做exporter 。目前互联网公司常用的组件大部分都有exporter可以直接使用,比如Varnish、Haproxy、Nginx、MySQL、Linux系统信息(包括磁盘、内存、CPU、网络等等)。
Prometheus部署
1. 修改 grafana-service.yaml 文件
使用git下载Prometheus项目1
2
3
4
5
6
7
8
9
10
11
12[root@k8s-master01 plugin]# mkdir prometheus
[root@k8s-master01 plugin]# cd prometheus/
[root@k8s-master01 prometheus]# git clone https://github.com/coreos/kube-prometheus.git
正克隆到 'kube-prometheus'...
remote: Enumerating objects: 4, done.
remote: Counting objects: 100% (4/4), done.
remote: Compressing objects: 100% (4/4), done.
remote: Total 8171 (delta 0), reused 1 (delta 0), pack-reused 8167
接收对象中: 100% (8171/8171), 4.56 MiB | 57.00 KiB/s, done.
处理 delta 中: 100% (4936/4936), done.
[root@k8s-master01 prometheus]# cd kube-prometheus/manifests/
[root@k8s-master01 manifests]# vim grafana-service.yaml
使用 nodepode 方式访问 grafana:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16apiVersion: v1
kind: Service
metadata:
labels:
app: grafana
name: grafana
namespace: monitoring
spec:
type: NodePort # 添加
ports:
- name: http
port: 3000
targetPort: http
nodePort: 30100 # 添加
selector:
app: grafana
2. 修改 修改 prometheus-service.yaml
1 | apiVersion: v1 |
3. 修改alertmanager-service.yaml
1 | apiVersion: v1 |
4. kubectl apply 部署
进入目录kube-prometheus执行kubectl apply -f manifests/
报错1
2
3
4
5
6
7
8
9
10
11
12
13
14unable to recognize "../manifests/alertmanager-alertmanager.yaml": no matches for kind "Alertmanager" in version "monitoring.coreos.com/v1"
unable to recognize "../manifests/alertmanager-serviceMonitor.yaml": no matches for kind "ServiceMonitor" in version "monitoring.coreos.com/v1"
unable to recognize "../manifests/grafana-serviceMonitor.yaml": no matches for kind "ServiceMonitor" in version "monitoring.coreos.com/v1"
unable to recognize "../manifests/kube-state-metrics-serviceMonitor.yaml": no matches for kind "ServiceMonitor" in version "monitoring.coreos.com/v1"
unable to recognize "../manifests/node-exporter-serviceMonitor.yaml": no matches for kind "ServiceMonitor" in version "monitoring.coreos.com/v1"
unable to recognize "../manifests/prometheus-operator-serviceMonitor.yaml": no matches for kind "ServiceMonitor" in version "monitoring.coreos.com/v1"
unable to recognize "../manifests/prometheus-prometheus.yaml": no matches for kind "Prometheus" in version "monitoring.coreos.com/v1"
unable to recognize "../manifests/prometheus-rules.yaml": no matches for kind "PrometheusRule" in version "monitoring.coreos.com/v1"
unable to recognize "../manifests/prometheus-serviceMonitor.yaml": no matches for kind "ServiceMonitor" in version "monitoring.coreos.com/v1"
unable to recognize "../manifests/prometheus-serviceMonitorApiserver.yaml": no matches for kind "ServiceMonitor" in version "monitoring.coreos.com/v1"
unable to recognize "../manifests/prometheus-serviceMonitorCoreDNS.yaml": no matches for kind "ServiceMonitor" in version "monitoring.coreos.com/v1"
unable to recognize "../manifests/prometheus-serviceMonitorKubeControllerManager.yaml": no matches for kind "ServiceMonitor" in version "monitoring.coreos.com/v1"
unable to recognize "../manifests/prometheus-serviceMonitorKubeScheduler.yaml": no matches for kind "ServiceMonitor" in version "monitoring.coreos.com/v1"
unable to recognize "../manifests/prometheus-serviceMonitorKubelet.yaml": no matches for kind "ServiceMonitor" in version "monitoring.coreos.com/v1"
创建成功后查看1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23[root@k8s-master01 manifests]# kubectl get svc -n monitoring
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
alertmanager-main NodePort 10.102.129.38 <none> 9093:30300/TCP 15s
alertmanager-operated ClusterIP None <none> 9093/TCP,6783/TCP 8s
grafana NodePort 10.103.207.222 <none> 3000:30100/TCP 14s
kube-state-metrics ClusterIP None <none> 8443/TCP,9443/TCP 14s
node-exporter ClusterIP None <none> 9100/TCP 14s
prometheus-adapter ClusterIP 10.104.146.228 <none> 443/TCP 13s
prometheus-k8s NodePort 10.100.247.74 <none> 9090:30200/TCP 12s
prometheus-operator ClusterIP None <none> 8080/TCP 15s
[root@k8s-master01 manifests]# kubectl get pods -n monitoring
NAME READY STATUS RESTARTS AGE
alertmanager-main-0 2/2 Running 1 111s
grafana-7dc5f8f9f6-r9w78 1/1 Running 0 117s
kube-state-metrics-5cbd67455c-q5hlh 4/4 Running 0 97s
node-exporter-5bjhk 2/2 Running 0 116s
node-exporter-n84tr 2/2 Running 0 115s
node-exporter-xbz84 2/2 Running 0 115s
prometheus-adapter-668748ddbd-c9ws6 1/1 Running 0 115s
prometheus-k8s-0 3/3 Running 1 101s
prometheus-k8s-1 3/3 Running 1 101s
prometheus-operator-7447bf4dcb-jfmsn 1/1 Running 0 117s
[root@k8s-master01 manifests]#
访问 prometheusprometheus
对应的 nodeport 端口为 30200,访问http://MasterIP:30200
通过访问http://MasterIP:30200/target可以看到 prometheus 已经成功连接上了 k8s 的 apiserver
节点全部健康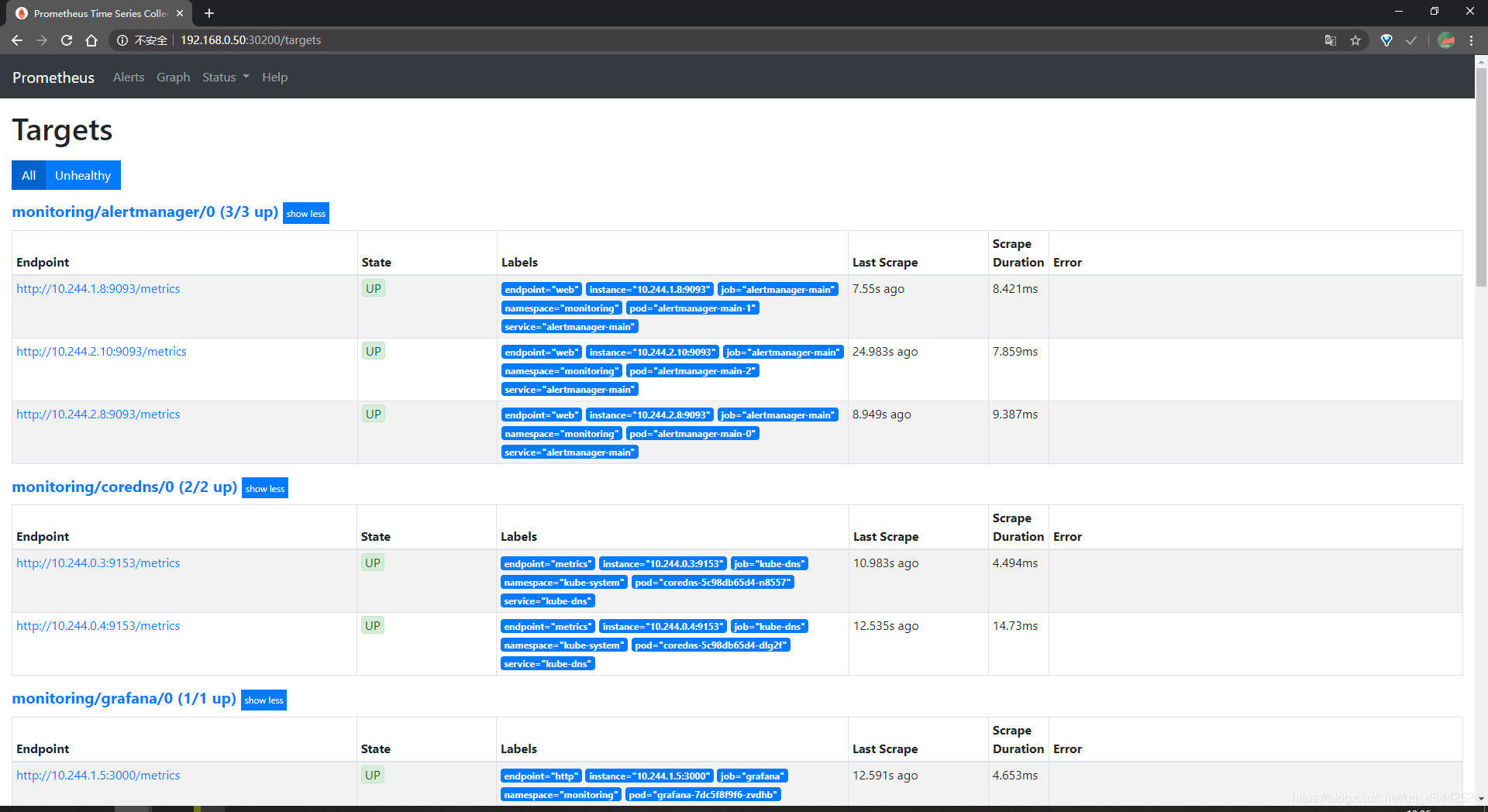
prometheus 的 WEB 界面上提供了基本的查询 K8S 集群中每个 POD 的 CPU 使用情况sum by (pod_name)( rate(container_cpu_usage_seconds_total{image!="", pod_name!=""}[1m] ) )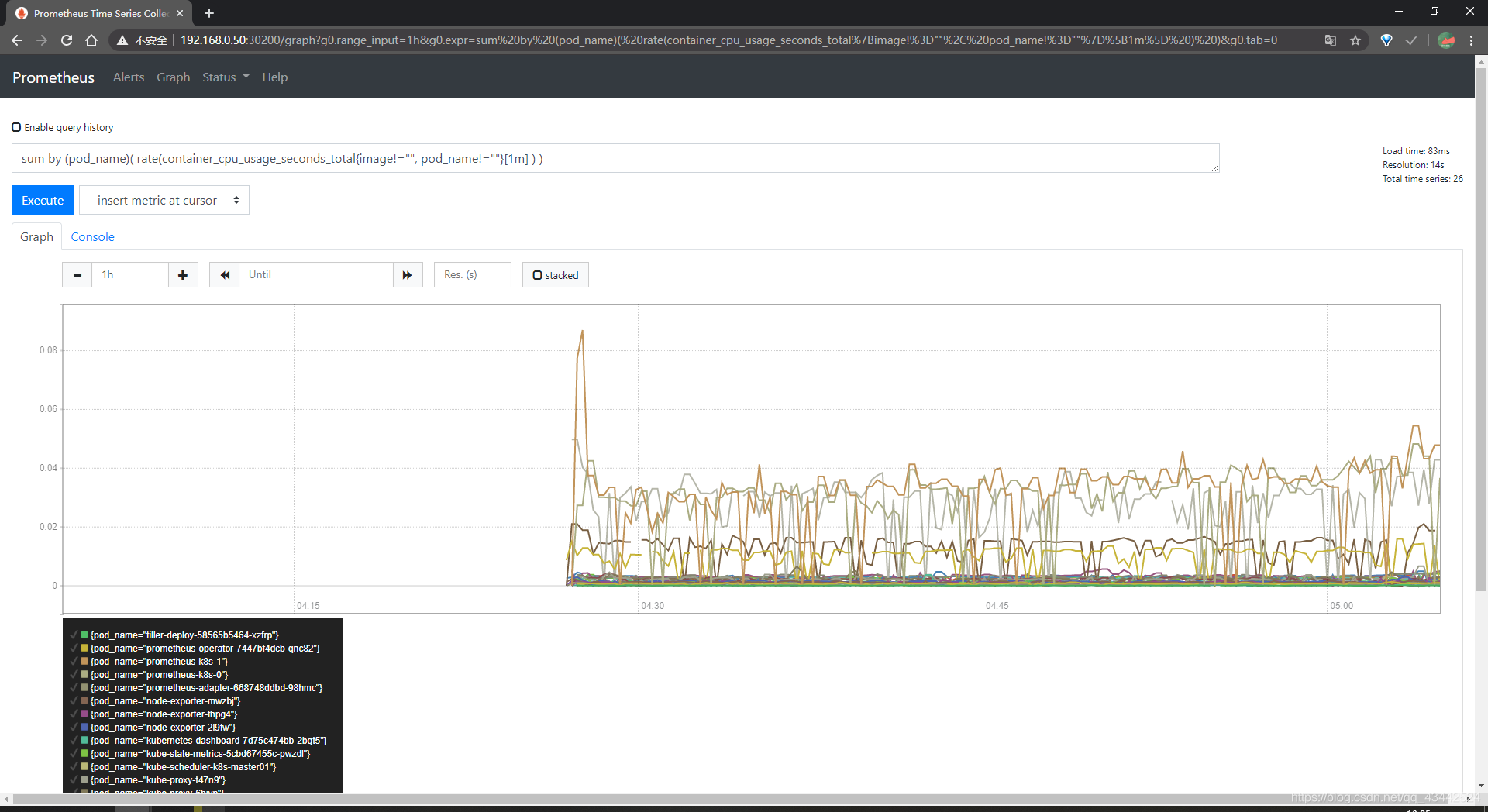
上述的查询有出现数据,说明 node-exporter 往 prometheus 中写入数据正常
访问 grafana查看
grafana 服务暴露的端口号:1
2kubectl getservice-n monitoring | grep grafana
grafana NodePort 10.107.56.143 <none> 3000:30100/TCP
浏览器访问http://MasterIP:30100
用户名密码默认 admin/admin
查看Kubernetes API server的数据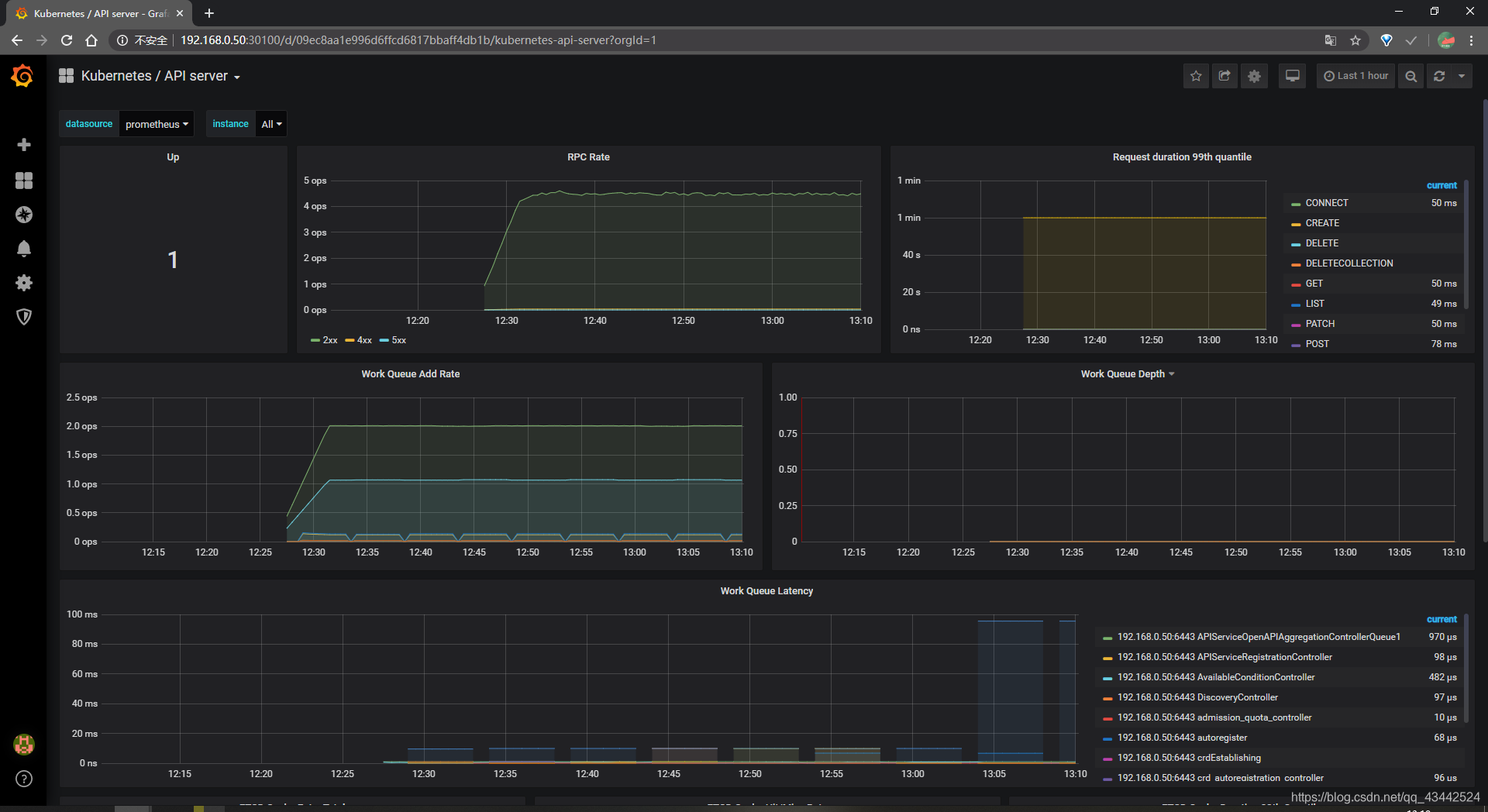
什么是 Helm
Helm官方网站:The package manager for Kubernetes
在没使用 helm 之前,向 kubernetes 部署应用,我们要依次部署 deployment、svc 等,步骤较繁琐。况且随着很多项目微服务化,复杂的应用在容器中部署以及管理显得较为复杂。
Helm 通过打包的方式,支持发布的版本管理和控制,很大程度上简化了 Kubernetes 应用的部署和管理Helm 本质就是让 K8s 的应用管理(Deployment,Service 等 ) 可配置,能动态生成,通过动态生成 K8s 资源清单文件(deployment.yaml,service.yaml),然后调用 Kubectl 自动执行 K8s 资源部署
Helm 是官方提供的类似于 YUM 的包管理器,是部署环境的流程封装。
Helm 有两个重要的概念:chart 和releasechart
- chart 是创建一个应用的信息集合,包括各种 Kubernetes 对象的配置模板、参数定义、依赖关系、文档说明等。chart 是应用部署的自包含逻辑单元。可以将 chart 想象成 apt、yum 中的软件安装包
- release 是 chart 的运行实例,代表了一个正在运行的应用。当 chart 被安装到 Kubernetes 集群,就生成一个 release。chart 能够多次安装到同一个集群,每次安装都是一个 release
Helm 包含两个组件:Helm 客户端和 Tiller 服务器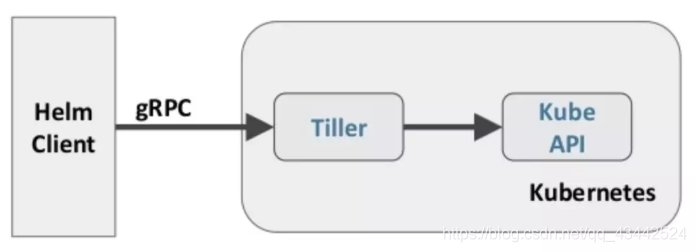
Helm 客户端负责 chart 和 release 的创建和管理以及和 Tiller 的交互。
Tiller 服务器运行在 Kubernetes 集群中,它会处理 Helm 客户端的请求,与 Kubernetes API Server 交互
Helm 2.13. 1 部署
1. 下载安装包
1 | wget https://storage.googleapis.com/kubernetes-helm/helm-v2.13.1-linux-amd64.tar.gz |
2. 创建 rbac-config.yaml 文件
1 | apiVersion: v1 |
将yaml文件部署下去后,使用helm init --service-account tiller --skip-refresh命令初始化Heml
]]>如果下载镜像失败 需要自己下载镜像导入到Docker中(三台节点)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
serviceaccount/tiller unchanged
clusterrolebinding.rbac.authorization.k8s.io/tiller created
[root@k8s-master01 helm]# docker load -i helm-tiller.tar
3fc64803ca2d: Loading layer [==================================================>] 4.463MB/4.463MB
79395a173ae6: Loading layer [==================================================>] 6.006MB/6.006MB
c33cd2d4c63e: Loading layer [==================================================>] 37.16MB/37.16MB
d727bd750bf2: Loading layer [==================================================>] 36.89MB/36.89MB
Loaded image: gcr.io/kubernetes-helm/tiller:v2.13.1
[root@k8s-master01 helm]# helm init --service-account tiller --skip-refresh
Creating /root/.helm
Creating /root/.helm/repository
Creating /root/.helm/repository/cache
Creating /root/.helm/repository/local
Creating /root/.helm/plugins
Creating /root/.helm/starters
Creating /root/.helm/cache/archive
Creating /root/.helm/repository/repositories.yaml
Adding stable repo with URL: https://kubernetes-charts.storage.googleapis.com
Adding local repo with URL: http://127.0.0.1:8879/charts
$HELM_HOME has been configured at /root/.helm.
Tiller (the Helm server-side component) has been installed into your Kubernetes Cluster.
Please note: by default, Tiller is deployed with an insecure 'allow unauthenticated users' policy.
To prevent this, run `helm init` with the --tiller-tls-verify flag.
For more information on securing your installation see: https://docs.helm.sh/using_helm/#securing-your-helm-installation
Happy Helming!
root@k8s-master01 helm]# helm version
Client: &version.Version{SemVer:"v2.13.1", GitCommit:"618447cbf203d147601b4b9bd7f8c37a5d39fbb4", GitTreeState:"clean"}
Server: &version.Version{SemVer:"v2.13.1", GitCommit:"618447cbf203d147601b4b9bd7f8c37a5d39fbb4", GitTreeState:"clean"}
[root@k8s-master01 helm]#
实验要求
1、 安装配置LVS负载均衡
2、 安装配置LVS高可用负载均衡
拓扑图: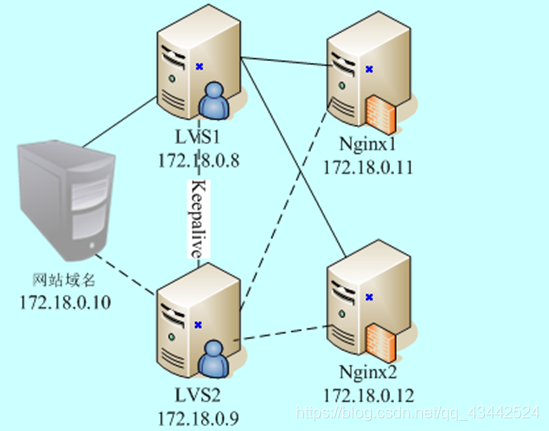
LVS介绍
负载均衡工作模式
1. NAT模式
Virtualserver via Network address translation(VS/NAT) 这个是通过网络地址转换的方法来实现调度的。
首先调度器(LB)接收到客户的请求数据包时(请求的目的IP为VIP),根据调度算法决定将请求发送给哪个后端的真实服务器(RS)。然后调度就把客户端发送的请求数据包的目标IP地址及端口改成后端真实服务器的IP地址(RIP),这样真实服务器(RS)就能够接收到客户的请求数据包了。真实服务器响应完请求后,查看默认路由(NAT模式下我们需要把RS的默认路由设置为LB服务器。)把响应后的数据包发送给LB,LB再接收到响应包后,把包的源地址改成虚拟地址(VIP)然后发送回给客户端。
调度过程IP包详细图:
原理图简述:
客户端请求数据,目标IP为VIP
请求数据到达LB服务器,LB根据调度算法将目的地址修改为RIP地址及对应端口(此RIP地址是根据调度算法得出的。)并在连接HASH表中记录下这个连接。
- 数据包从LB服务器到达RS服务器webserver,然后webserver进行响应。Webserver的网关必须是LB,然后将数据返回给LB服务器。
- 收到RS的返回后的数据,根据连接HASH表修改源地址VIP&目标地址CIP,及对应端口80.然后数据就从LB出发到达客户端。
客户端收到的就只能看到VIP\DIP信息。
NAT模式优缺点:
- NAT技术将请求的报文和响应的报文都需要通过LB进行地址改写,因此网站访问量比较大的时候LB负载均衡调度器有比较大的瓶颈,一般要求最多只能10-20台节点
- 只需要在LB上配置一个公网IP地址就可以
- 每台内部的节点服务器的网关地址必须是调度器LB的内网地址
- NAT模式支持对IP地址和端口进行转换。即用户请求的端口和真实服务器的端口可以不一致
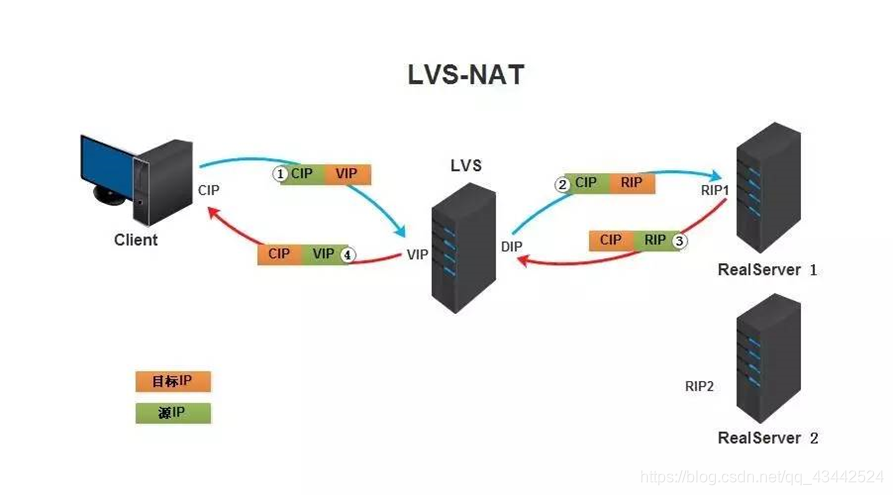
客户端将请求发往前端的负载均衡器,请求报文源地址是CIP(客户端IP),后面统称为CIP),目标地址为VIP(负载均衡器前端地址,后面统称为VIP)
负载均衡器收到报文后,发现请求的是在规则里面存在的地址,那么它将客户端请求报文的目标地址改为了后端服务器的RIP地址并将报文根据算法发送出去
报文送到Real Server后,由于报文的目标地址是自己,所以会响应该请求,并将响应报文返还给LVS。
然后lvs将此报文的源地址修改为本机并发送给客户端。
优点: 集群中的物理服务器可以使用任何支持TCP/IP操作系统,只有负载均衡器需要一个合法的IP地址。
缺点: 扩展性有限。当服务器节点(普通PC服务器)增长过多时,负载均衡器将成为整个系统的瓶颈,因为所有的请求包和应答包的流向都经过负载均衡器。当服务器节点过多时,大量的数据包都交汇在负载均衡器那,速度就会变慢
2. TUN(隧道)模式
virtual server via ip tunneling模式:采用NAT模式时,由于请求和响应的报文必须通过调度器地址重写,当客户请求越来越多时,调度器处理能力将成为瓶颈。为了解决这个问题,调度器把请求的报文通过IP隧道转发到真实的服务器。真实的服务器将响应处理后的数据直接返回给客户端。这样调度器就只处理请求入站报文,由于一般网络服务应答数据比请求报文大很多,采用VS/TUN模式后,集群系统的最大吞吐量可以提高10倍。 VS/TUN的工作流程图如下所示,它和NAT模式不同的是,它在LB和RS之间的传输不用改写IP地址。而是把客户请求包封装在一个IP tunnel里面,然后发送给RS节点服务器,节点服务器接收到之后解开IP tunnel后,进行响应处理。并且直接把包通过自己的外网地址发送给客户不用经过LB服务器。
Tunnel原理流程图: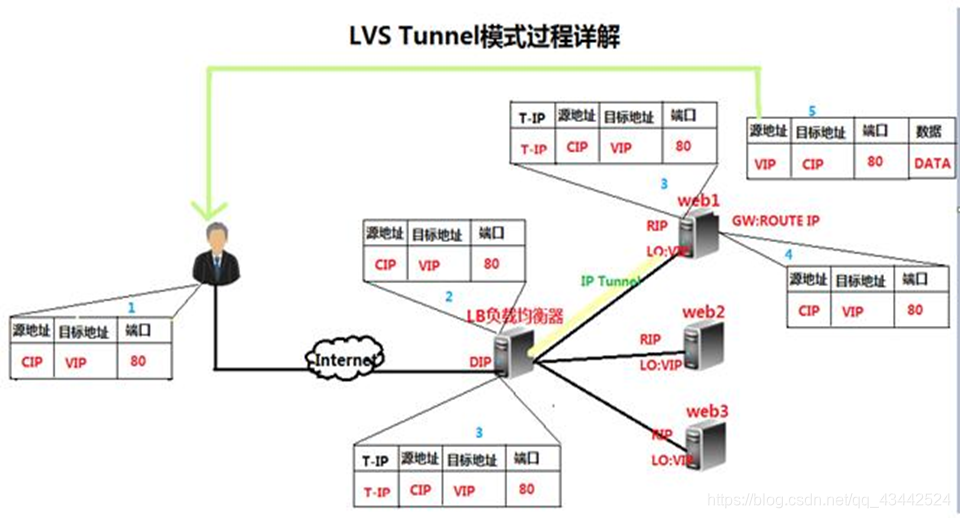
原理图过程简述:
- 客户请求数据包,目标地址VIP发送到LB上。
- LB接收到客户请求包,进行IP Tunnel封装。即在原有的包头加上IP Tunnel的包头。然后发送出去。
- RS节点服务器根据IP Tunnel包头信息(此时就又一种逻辑上的隐形隧道,只有LB和RS之间懂)收到请求包,然后解开IP Tunnel包头信息,得到客户的请求包并进行响应处理。
- 响应处理完毕之后,RS服务器使用自己的出公网的线路,将这个响应数据包发送给客户端。源IP地址还是VIP地址
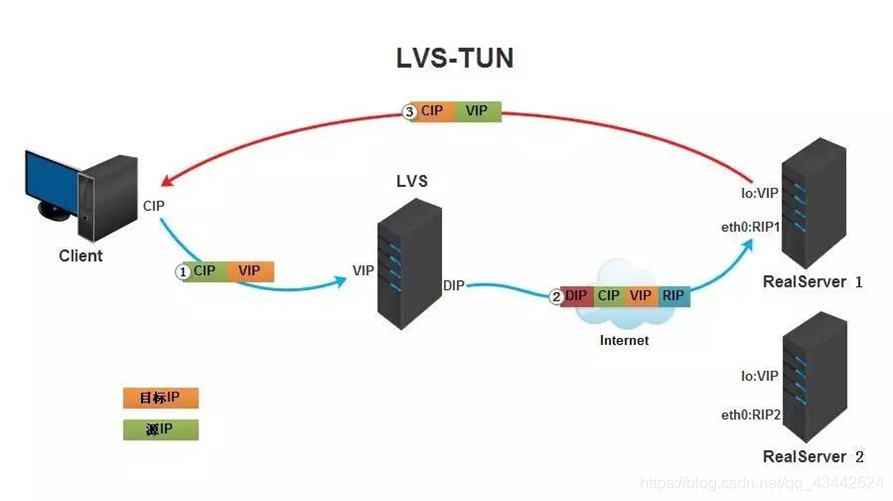
- 客户端将请求发往前端的负载均衡器,请求报文源地址是CIP,目标地址为VIP。
- 负载均衡器收到报文后,发现请求的是在规则里面存在的地址,那么它将在客户端请求报文的首部再封装一层IP报文,将源地址改为DIP,目标地址改为RIP,并将此包发送给RS。
- RS收到请求报文后,会首先拆开第一层封装,然后发现里面还有一层IP首部的目标地址是自己lo接口上的VIP,所以会处理次请求报文,并将响应报文通过lo接口送给eth0网卡直接发送给客户端。
注意: 需要设置lo接口的VIP不能在共网上出现。
总结:
- TUNNEL 模式必须在所有的 realserver 机器上面绑定 VIP 的 IP 地址
- TUNNEL 模式的 vip ——>realserver 的包通信通过 TUNNEL 模式,不管是内网和外网都能通信,所以不需要 lvs vip 跟 realserver 在同一个网段内
- TUNNEL 模式 realserver 会把 packet 直接发给 client 不会给 lvs 了
- TUNNEL 模式走的隧道模式,所以运维起来比较难,所以一般不用。
优点: 负载均衡器只负责将请求包分发给后端节点服务器,而RS将应答包直接发给用户。所以,减少了负载均衡器的大量数据流动,负载均衡器不再是系统的瓶颈,就能处理很巨大的请求量,这种方式,一台负载均衡器能够为很多RS进行分发。而且跑在公网上就能进行不同地域的分发。
缺点: 隧道模式的RS节点需要合法IP,这种方式需要所有的服务器支持”IP Tunneling”(IP Encapsulation)协议,服务器可能只局限在部分Linux系统上。
3. DR模式(直接路由模式)
Virtual server via direct routing (vs/dr) DR模式是通过改写请求报文的目标MAC地址,将请求发给真实服务器的,而真实服务器响应后的处理结果直接返回给客户端用户。同TUN模式一样,DR模式可以极大的提高集群系统的伸缩性。而且DR模式没有IP隧道的开销,对集群中的真实服务器也没有必要必须支持IP隧道协议的要求。但是要求调度器LB与真实服务器RS都有一块网卡连接到同一物理网段上,必须在同一个局域网环境。 DR模式是互联网使用比较多的一种模式。
DR模式原理图: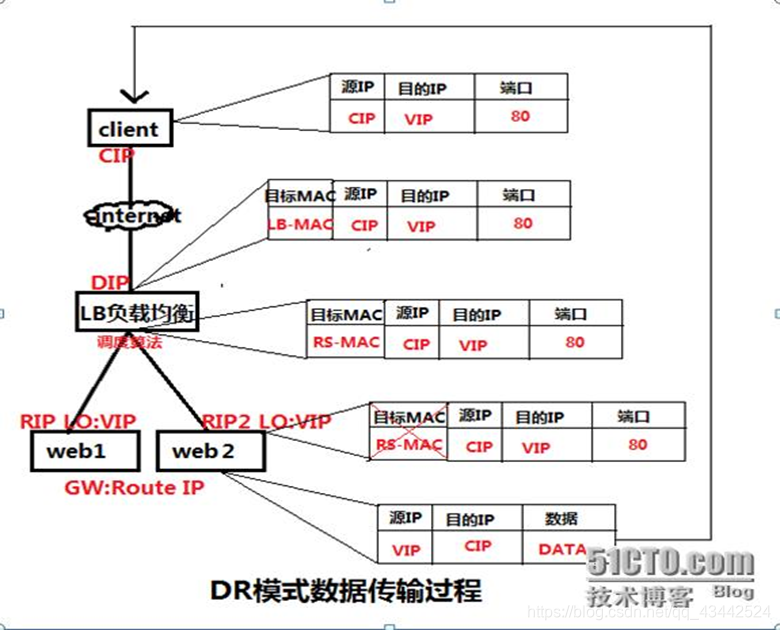
DR模式原理过程简述:
VS/DR模式的工作流程图如上图所示,它的连接调度和管理与NAT和TUN中的一样,它的报文转发方法和前两种不同。DR模式将报文直接路由给目标真实服务器。在DR模式中,调度器根据各个真实服务器的负载情况,连接数多少等,动态地选择一台服务器,不修改目标IP地址和目标端口,也不封装IP报文,而是将请求报文的数据帧的目标MAC地址改为真实服务器的MAC地址。然后再将修改的数据帧在服务器组的局域网上发送。因为数据帧的MAC地址是真实服务器的MAC地址,并且又在同一个局域网。那么根据局域网的通讯原理,真实复位是一定能够收到由LB发出的数据包。真实服务器接收到请求数据包的时候,解开IP包头查看到的目标IP是VIP。(此时只有自己的IP符合目标IP才会接收进来,所以我们需要在本地的回环借口上面配置VIP。
另:由于网络接口都会进行ARP广播响应,但集群的其他机器都有这个VIP的lo接口,都响应就会冲突。所以我们需要把真实服务器的lo接口的ARP响应关闭掉。)然后真实服务器做成请求响应,之后根据自己的路由信息将这个响应数据包发送回给客户,并且源IP地址还是VIP。
DR模式小结:
- 通过在调度器LB上修改数据包的目的MAC地址实现转发。注意源地址仍然是CIP,目的地址仍然是VIP地址。
- 请求的报文经过调度器,而RS响应处理后的报文无需经过调度器LB,因此并发访问量大时使用效率很高(和NAT模式比)
- 因为DR模式是通过MAC地址改写机制实现转发,因此所有RS节点和调度器LB只能在一个局域网里面
- RS主机需要绑定VIP地址在LO接口上,并且需要配置ARP抑制。
- RS节点的默认网关不需要配置成LB,而是直接配置为上级路由的网关,能让RS直接出网就可以。
- 由于DR模式的调度器仅做MAC地址的改写,所以调度器LB就不能改写目标端口,那么RS服务器就得使用和VIP相同的端口提供服务
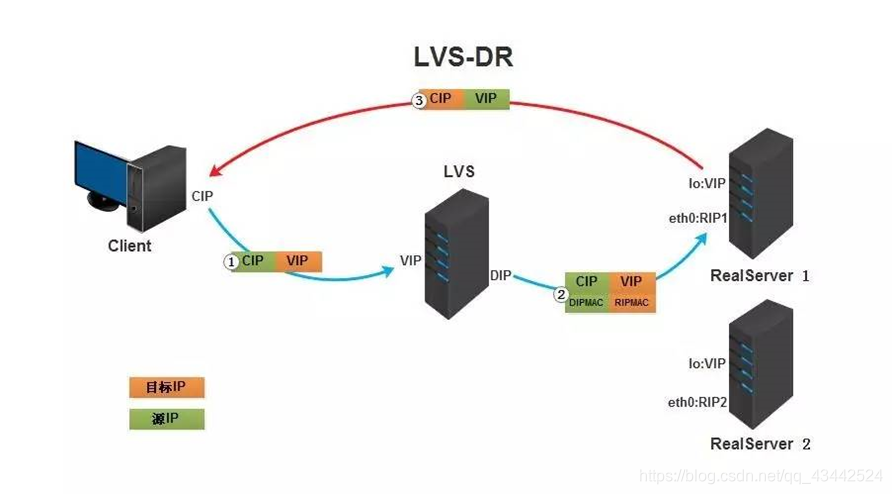
- 客户端将请求发往前端的负载均衡器,请求报文源地址是CIP,目标地址为VIP。
- 负载均衡器收到报文后,发现请求的是在规则里面存在的地址,那么它将客户端请求报文的源MAC地址改为自己DIP的MAC地址,目标MAC改为了RIP的MAC地址,并将此包发送给RS。
- RS发现请求报文中的目的MAC是自己,就会将次报文接收下来,处理完请求报文后,将响应报文通过lo接口送给eth0网卡直接发送给客户端。
注意: 需要设置lo接口的VIP不能响应本地网络内的arp请求。
总结:
- 通过在调度器 LB 上修改数据包的目的 MAC 地址实现转发。注意源地址仍然是 CIP,目的地址仍然是 VIP 地址。
- 请求的报文经过调度器,而 RS 响应处理后的报文无需经过调度器 LB,因此并发访问量大时使用效率很高(和 NAT 模式比)
- 因为 DR 模式是通过 MAC 地址改写机制实现转发,因此所有 RS 节点和调度器 LB 只能在一个局域网里面
- RS 主机需要绑定 VIP 地址在 LO 接口(掩码32 位)上,并且需要配置 ARP 抑制。
- RS 节点的默认网关不需要配置成 LB,而是直接配置为上级路由的网关,能让 RS 直接出网就可以。
- 由于 DR 模式的调度器仅做 MAC 地址的改写,所以调度器 LB 就不能改写目标端口,那么 RS 服务器就得使用和 VIP 相同的端口提供服务。
- 直接对外的业务比如WEB等,RS 的IP最好是使用公网IP。对外的服务,比如数据库等最好使用内网IP。
优点:
和TUN(隧道模式)一样,负载均衡器也只是分发请求,应答包通过单独的路由方法返回给客户端。与VS-TUN相比,VS-DR这种实现方式不需要隧道结构,因此可以使用大多数操作系统做为物理服务器。 DR模式的效率很高,但是配置稍微复杂一点,因此对于访问量不是特别大的公司可以用haproxy/nginx取代。日1000-2000W PV或者并发请求1万一下都可以考虑用haproxy/nginx。
缺点: 所有 RS 节点和调度器 LB 只能在一个局域网里面。
在LVS1配置LVS负载均衡
1. 使用centos镜像生成lvs-keep镜像
- 启动centos容器并进入
docker run -d --privileged centos:v1 /usr/sbin/init
2) 在centos容器中使用yum方式安装lvs和keepalived1
2yum install ipvsadm
yum install keepalived
3) 保存容器为镜像docker commit 容器ID lvs-keep
2. 使用nginx镜像启动nginx1和nginx2两个容器
1) 创建docker网络docker network create --subnet=172.18.0.0/16 cluster
2) 查看宿主机上的docker网络类型种类docker network ls
3) 启动容器nginx1,nginx2 设定地址为172.18.0.11, 172.18.0.12docker run -d --privileged --net cluster --ip 172.18.0.11 --name nginx1 nginx /usr/sbin/initdocker run -d --privileged --net cluster --ip 172.18.0.12 --name nginx2 nginx /usr/sbin/init1
2
3
4
5[root@localhost ~]# docker run -d --privileged --net cluster --ip 172.18.0.11 --name nginx1 nginx /usr/sbin/init
8deb9befa966726e16bee8fb4a8eb63ef0c47d66f507092b3bad63e11a348ffd
[root@localhost ~]# docker run -d --privileged --net cluster --ip 172.18.0.12 --name nginx2 nginx /usr/sbin/init
f2fbc74a948461060345899ffd5d0e4e82b7012e2fff793daca3aa78fa4e90b9
[root@localhost ~]#
3. 使用lvs-keep镜像启用LVS1容器,配置LVS负载均衡
在宿主机上安装ipvsadm
yum install ipvsadm# modprobe ip_vs //装入ip_vs模块
1) 启动容器LVS1,设定地址为172.18.0.8docker run -d --privileged --net cluster --ip 172.18.0.8 --name LVS1 lvs-keep /usr/sbin/init
2) 进入LVS1容器lsmod |grep ip_vs列出装载的模块
2
3
4
ip_vs 145497 0
nf_conntrack 139224 7 ip_vs,nf_nat,nf_nat_ipv4,xt_conntrack,nf_nat_masquerade_ipv4,nf_conntrack_netlink,nf_conntrack_ipv4
libcrc32c 12644 4 xfs,ip_vs,nf_nat,nf_conntrack
3) 在LVS1创建VIP调度地址ifconfig eth0:0 172.18.0.10 netmask 255.255.255.255
4) 在LVS1创建虚拟服务器,使用轮询方式:ipvsadm -At 172.18.0.10:80 -s rr
5) 在LVS1添加nginx1和nginx2两台服务器节点,采用DR直接路由模式ipvsadm -at 172.18.0.10:80 -r 172.18.0.11:80 -gipvsadm -at 172.18.0.10:80 -r 172.18.0.12:80 -g
1 | [root@58a00cfe8c9d /]# ifconfig eth0:0 172.18.0.10 netmask 255.255.255.255 |
6) 在nginx1和nginx2两台服务器节点,创建VIP应答地址ifconfig lo:0 172.18.0.10 netmask 255.255.255.255
7) 在nginx1和nginx2两台服务器节点,屏蔽ARP请求1
2
3
4echo "1" > /proc/sys/net/ipv4/conf/lo/arp_ignore
echo "1" > /proc/sys/net/ipv4/conf/all/arp_ignore
echo "2" > /proc/sys/net/ipv4/conf/lo/arp_announce
echo "2" > /proc/sys/net/ipv4/conf/all/arp_announce
8) 在LVS1中,ipvsadm -L 检查配置情况1
2
3
4
5
6
7
8[root@58a00cfe8c9d /]# ipvsadm -L
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 58a00cfe8c9d:http rr
-> nginx1.cluster:http Route 1 0 0
-> nginx2.cluster:http Route 1 0 0
[root@58a00cfe8c9d /]#
9) 在宿主机中访问http://172.18.0.10,刷新时轮流访问两台节点服务器1
2
3
4
5[root@localhost ~]# curl 172.18.0.10
nginx2
[root@localhost ~]# curl 172.18.0.10
nginx1
[root@localhost ~]#
使用KeepAlive配置LVS高可用
在两台LVS服务器安装配置KeepAlive,使得两台服务器互为备份并支持负载均衡
保持任务一中nginx1和nginx2两台服务器节点不变,重新启动容器LVS1和LVS2
1. 使用lvs-keep镜像启用LVS1和LVS2容器,配置LVS负载均衡
注意:需要在宿主机安装ipvsadm,# modprobe ip_vs //装入ip_vs模块
1) 启动容器LVS1,设定地址为172.18.0.8docker run -d --privileged --net cluster --ip 172.18.0.8 --name LVS1 lvs-keep /usr/sbin/init
2) 启动容器LVS2,设定地址为172.18.0.9docker run -d --privileged --net cluster --ip 172.18.0.9 --name LVS2 lvs-keep /usr/sbin/init
3) 编辑LVS1和LVS2中/etc/ keepalived /keepalived.conf文件
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
global_defs {
notification_email {
[email protected]
[email protected]
[email protected]
}
notification_email_from [email protected]
smtp_server 192.168.200.1
smtp_connect_timeout 30
router_id LVS1
vrrp_skip_check_adv_addr #跳过vrrp报文地址检查
#vrrp_strict #严格遵守vrrp协议
vrrp_garp_interval 3 #在一个网卡上每组gratuitous arp消息之间的延迟时间,默认为0
vrrp_gna_interval 3 #在一个网卡上每组na消息之间的延迟时间,默认为0
}
vrrp_instance VI_1 {
state MASTER #LVS2设置为BACKUP
interface eth0
virtual_router_id 51
priority 100 #L 设置权重
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
172.18.0.10
}
}
virtual_server 172.18.0.10 80 { #配置虚拟服务器
delay_loop 6 #设置健康检查时间,单位是秒
lb_algo rr #设置负载调度算法,默认为rr即轮询算法
lb_kind DR #设置LVS实现LB机制,有NAT、TUNN和DR三个模式可选
persistence_timeout 0 #会话保持时间,单位为秒,设为0可以看到刷新效果
protocol TCP #指定转发协议类型,有TCP和UDP两种
real_server 172.18.0.11 80 { #配置服务器节点
weight 1
TCP_CHECK { #配置节点权值,数字越大权值越高
connect_timeout 3 #超时时间
retry 3 #重试次数
delay_before_retry 3 #重试间隔
}
}
real_server 172.18.0.12 80 {
weight 1
TCP_CHECK {
connect_timeout 3
retry 3
delay_before_retry 3
}
}
}
2. 验证KeepAlive配置LVS高可用集群
1) 在两台服务器重启keepalived服务,ipvsadm -L检查配置情况1
2
3
4
5
6
7
8[root@ef99a927fc2d /]# ipvsadm -L
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 172.18.0.10:http rr
-> nginx1.cluster:http Route 1 0 0
-> nginx2.cluster:http Route 1 0 0
[root@ef99a927fc2d /]#
1 | [root@a033e26a1fd8 /]# ipvsadm -L |
2) 在宿主机中访问http://172.18.0.10,刷新时轮流访问两台节点服务器1
2
3
4
5[root@localhost ~]# curl 172.18.0.10
nginx2
[root@localhost ~]# curl 172.18.0.10
nginx1
[root@localhost ~]#
3) 在LVS1服务器#ifconfig eth0 down //当掉服务器网卡
4) 在宿主机中访问http://172.18.0.10,刷新时轮流访问两台节点服务器
5) 在LVS2中,#ipvsadm -L //检查配置和连接情况
lvs2中可以看到InActConn增加
因为lvs1将eth0关闭以后, 有lvs2接管服务1
2
3
4
5
6
7
8[root@ef99a927fc2d /]# ipvsadm -L
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP ef99a927fc2d:http rr
-> nginx1.cluster:http Route 1 0 3
-> nginx2.cluster:http Route 1 0 3
[root@ef99a927fc2d /]#
上几章写了Kubernetes的基本概念与集群搭建
接下来将深入探索Pod的应用、配置、调度、升级及扩缩容,讲述Kubernetes容器编排。
本章将对Kubernetes如何发布与管理容器应用进行详细说明和示例,主要包括Pod和容器的使用、应用配置管理、Pod的控制和调度管理、Pod的升级和回滚,以及Pod的扩缩容机制等内容
深入掌握Pod
Pod定义
Pod定义文件的yaml格式完整版1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76apiVersion: v1 #必选,版本号,例如v1,版本号必须可以用 kubectl api-versions 查询到 .
kind: Pod #必选,Pod
metadata: #必选,元数据
name: string #必选,Pod名称
namespace: string #必选,Pod所属的命名空间,默认为"default"
labels: #自定义标签
- name: string #自定义标签名字
annotations: #自定义注释列表
- name: string
spec: #必选,Pod中容器的详细定义
containers: #必选,Pod中容器列表
- name: string #必选,容器名称,需符合RFC 1035规范
image: string #必选,容器的镜像名称
imagePullPolicy: [ Always|Never|IfNotPresent ] #获取镜像的策略 Alawys表示下载镜像 IfnotPresent表示优先使用本地镜像,否则下载镜像,Nerver表示仅使用本地镜像
command: [string] #容器的启动命令列表,如不指定,使用打包时使用的启动命令
args: [string] #容器的启动命令参数列表
workingDir: string #容器的工作目录
volumeMounts: #挂载到容器内部的存储卷配置
- name: string #引用pod定义的共享存储卷的名称,需用volumes[]部分定义的的卷名
mountPath: string #存储卷在容器内mount的绝对路径,应少于512字符
readOnly: boolean #是否为只读模式
ports: #需要暴露的端口库号列表
- name: string #端口的名称
containerPort: int #容器需要监听的端口号
hostPort: int #容器所在主机需要监听的端口号,默认与Container相同
protocol: string #端口协议,支持TCP和UDP,默认TCP
env: #容器运行前需设置的环境变量列表
- name: string #环境变量名称
value: string #环境变量的值
resources: #资源限制和请求的设置
limits: #资源限制的设置
cpu: string #Cpu的限制,单位为core数,将用于docker run --cpu-shares参数
memory: string #内存限制,单位可以为Mib/Gib,将用于docker run --memory参数
requests: #资源请求的设置
cpu: string #Cpu请求,容器启动的初始可用数量
memory: string #内存请求,容器启动的初始可用数量
livenessProbe: #对Pod内各容器健康检查的设置,当探测无响应几次后将自动重启该容器,检查方法有exec、httpGet和tcpSocket,对一个容器只需设置其中一种方法即可
exec: #对Pod容器内检查方式设置为exec方式
command: [string] #exec方式需要制定的命令或脚本
httpGet: #对Pod内个容器健康检查方法设置为HttpGet,需要制定Path、port
path: string
port: number
host: string
scheme: string
HttpHeaders:
- name: string
value: string
tcpSocket: #对Pod内个容器健康检查方式设置为tcpSocket方式
port: number
initialDelaySeconds: 0 #容器启动完成后首次探测的时间,单位为秒
timeoutSeconds: 0 #对容器健康检查探测等待响应的超时时间,单位秒,默认1秒
periodSeconds: 0 #对容器监控检查的定期探测时间设置,单位秒,默认10秒一次
successThreshold: 0
failureThreshold: 0
securityContext:
privileged: false
restartPolicy: [Always | Never | OnFailure] #Pod的重启策略,Always表示一旦不管以何种方式终止运行,kubelet都将重启,OnFailure表示只有Pod以非0退出码退出才重启,Nerver表示不再重启该Pod
nodeSelector: obeject #设置NodeSelector表示将该Pod调度到包含这个label的node上,以key:value的格式指定
imagePullSecrets: #Pull镜像时使用的secret名称,以key:secretkey格式指定
- name: string
hostNetwork: false #是否使用主机网络模式,默认为false,如果设置为true,表示使用宿主机网络
volumes: #在该pod上定义共享存储卷列表
- name: string #共享存储卷名称 (volumes类型有很多种)
emptyDir: {} #类型为emtyDir的存储卷,与Pod同生命周期的一个临时目录。为空值
hostPath: string #类型为hostPath的存储卷,表示挂载Pod所在宿主机的目录
path: string #Pod所在宿主机的目录,将被用于同期中mount的目录
secret: #类型为secret的存储卷,挂载集群与定义的secre对象到容器内部
scretname: string
items:
- key: string
path: string
configMap: #类型为configMap的存储卷,挂载预定义的configMap对象到容器内部
name: string
items:
- key: string
path: string
静态Pod
静态Pod是由kubelet进行管理的仅存在于特定Node上的Pod。
它们不能通过API Server进行管理,无法与ReplicationController、Deployment或者DaemonSet进行关联,并且kubelet无法对它们进行健康检查。
静态Pod总是由kubelet创建的,并且总在kubelet所在的Node上运行。创建静态Pod有两种方式:
- 配置文件方式
- HTTP方式
1
2
3
4
5
6
7
8
9
10
11
12
13
14apiVersion: v1
kind: Pod
metadata:
name: pod-demo
namespace: default
labels:
app: myapp
spec:
containers:
- name: myapp-1
image: plutoacharon/myapp:v1
- name: busybox-1
image: busybox:latest
command: - "/bin/sh" - "-c" - "sleep 3600"
Pod容器共享Volume
同一个Pod中的多个容器能够共享Pod级别的存储卷Volume。
Volume可以被定义为各种类型,多个容器各自进行挂载操作,将一个Volume挂载为容器内部需要的目录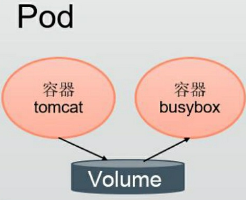
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
apiVersion: v1
kind: Pod
metadata:
name: test-pd
spec:
containers:
- image: k8s.gcr.io/test-webserver
name: test-container
volumeMounts:
- mountPath: /cache
name: cache-volume
volumes:
name: cache-volume
emptyDir: {}
emptyDir
当 Pod 被分配给节点时,首先创建emptyDir卷,并且只要该 Pod 在该节点上运行,该卷就会存在。
正如卷的名字所述,它最初是空的。Pod 中的容器可以读取和写入emptyDir卷中的相同文件,尽管该卷可以挂载到每个容器中的相同或不同路径上。
当出于任何原因从节点中删除 Pod 时,emptyDir中的数据将被永久删除
emptyDir的用法有:
暂存空间,例如用于基于磁盘的合并排序
用作长时间计算崩溃恢复时的检查点
Web服务器容器提供数据时,保存内容管理器容器提取的文件
ConfigMap概述
ConfigMap 功能在 Kubernetes1.2 版本中引入,许多应用程序会从配置文件、命令行参数或环境变量中读取配置信息。
ConfigMap API 给我们提供了向容器中注入配置信息的机制,ConfigMap 可以被用来保存单个属性,也可以用来保存整个配置文件或者 JSON 二进制大对象
ConfigMap供容器使用的典型用法如下。
- 生成为容器内的环境变量。
- 设置容器启动命令的启动参数(需设置为环境变量)
- 以Volume的形式挂载为容器内部的文件或目录。
ConfigMap以一个或多个key:value的形式保存在Kubernetes系统中供应用使用,既可以用于表示一个变量的值(例如apploglevel=info),也可以用于表示一个完整配置文件的内容(例如server.xml=<?xml…>…)
可以通过YAML配置文件或者直接使用kubectl create configmap命令行的方式来创建ConfigMap。
使用ConfigMap的限制条件使用ConfigMap的限制条件如下。
- ConfigMap必须在Pod之前创建。
- ConfigMap受Namespace限制,只有处于相同Namespace中的Pod才可以引用它。
- ConfigMap中的配额管理还未能实现。
- kubelet只支持可以被API Server管理的Pod使用ConfigMap。kubelet在本Node上通过 –manifest-url或–config自动创建的静态Pod将无法引用ConfigMap。
- 在Pod对ConfigMap进行挂载(volumeMount)操作时,在容器内部只能挂载为“目录”,无法挂载为“文件”。在挂载到容器内部后,在目录下将包含ConfigMap定义的每个item,如果在该目录下原来还有其他文件,则容器内的该目录将被挂载的ConfigMap覆盖。如果应用程序需要保留原来的其他文件,则需要进行额外的处理。可以将ConfigMap挂载到容器内部的临时目录,再通过启动脚本将配置文件复制或者链接到(cp或link命令)应用所用的实际配置目录下
容器内获取Pod信息(DownwardAPI)
我们知道,每个Pod在被成功创建出来之后,都会被系统分配唯一的名字、IP地址,并且处于某个Namespace中,那么我们如何在Pod的容器内获取Pod的这些重要信息呢?答案就是使用Downward API。
Downward API可以通过以下两种方式将Pod信息注入容器内部。
- 环境变量:用于单个变量,可以将Pod信息和Container信息注入容器内部。
- Volume挂载:将数组类信息生成为文件并挂载到容器内部。
Pod生命周期和重启策略
挂起(Pending):Pod已被Kubernetes系统接受,但有一个或者多个容器镜像尚未创建。等待时间包括调度Pod的时间和通过网络下载镜像的时间,这可能需要花点时间
运行中(Running):该Pod已经绑定到了一个节点上,Pod中所有的容器都已被创建。至少有一个容器正在运行,或者正处于启动或重启状态成功(Succeeded):Pod中的所有容器都被成功终止,并且不会再重启
失败(Failed):Pod中的所有容器都已终止了,并且至少有一个容器是因为失败终止。也就是说,容器以非0状态退出或者被系统终止
未知(Unknown):因为某些原因无法取得Pod的状态,通常是因为与Pod所在主机通信失败
Pod的重启策略(RestartPolicy)应用于Pod内的所有容器,并且仅在Pod所处的Node上由kubelet进行判断和重启操作。当某个容器异常退出或者健康检查失败时,kubelet将根据RestartPolicy的设置来进行相应的操作。Pod的重启策略包括Always、OnFailure和Never,默认值为Always。
- Always:当容器失效时,由kubelet自动重启该容器。
- OnFailure:当容器终止运行且退出码不为0时,由kubelet自动重启该容器。
- Never:不论容器运行状态如何,kubelet都不会重启该容器。
kubelet重启失效容器的时间间隔以sync-frequency乘以2n来计算,例如1、2、4、8倍等,最长延时5min,并且在成功重启后的10min后重置该时间。
Pod的重启策略与控制方式息息相关,当前可用于管理Pod的控制器包ReplicationController、Job、DaemonSet及直接通过kubelet管理(静态Pod)。每种控制器对Pod的重启策略要求如下
- RC和DaemonSet:必须设置为Always,需要保证该容器持续运行。
- Job:OnFailure或Never,确保容器执行完成后不再重启。
- kubelet:在Pod失效时自动重启它,不论将RestartPolicy设置为什么值,也不会对Pod进行健康检查
Pod健康检查和服务可用性检查
Kubernetes 对 Pod 的健康状态可以通过两类探针来检查:LivenessProbe 和ReadinessProbe,kubelet定期执行这两类探针来诊断容器的健康状况。
- LivenessProbe探针:用于判断容器是否存活(Running状态),如果LivenessProbe探针探测到容器不健康,则kubelet将杀掉该容器,并根据容器的重启策略做相应的处理。如果一个容器不包含LivenessProbe探针,那么kubelet认为该容器的LivenessProbe探针返回的值永远是Success。
- ReadinessProbe探针:用于判断容器服务是否可用(Ready状态),达到Ready状态的Pod才可以接收请求。对于被Service管理的Pod,Service与Pod Endpoint的关联关系也将基于Pod是否Ready进行设置。如果在运行过程中Ready状态变为False,则系统自动将其从Service的后端Endpoint列表中隔离出去,后续再把恢复到Ready状态的Pod加回后端Endpoint列表。这样就能保证客户端在访问Service时不会被转发到服务不可用的Pod实例上。
目录
填空题1
问题描述
一个包含有2019个结点的无向连通图,最少包含多少条边?
答案提交
这是一道结果填空的题,你只需要算出结果后提交即可。本题的结果为一个整数,在提交答案时只填写这个整数,填写多余的内容将无法得分。
答案 :2018
填空题2
问题描述
将LANQIAO中的字母重新排列,可以得到不同的单词,如LANQIAO、AAILNOQ等,注意这7个字母都要被用上,单词不一定有具体的英文意义。
请问,总共能排列如多少个不同的单词。
答案提交
这是一道结果填空的题,你只需要算出结果后提交即可。本题的结果为一个整数,在提交答案时只填写这个整数,填写多余的内容将无法得分。
答案 :2520
填空题3
问题描述
在计算机存储中,12.5MB是多少字节?
答案提交
这是一道结果填空的题,你只需要算出结果后提交即可。本题的结果为一个整数,在提交答案时只填写这个整数,填写多余的内容将无法得分。
答案 :13107200
填空题4
问题描述
由1对括号,可以组成一种合法括号序列:()。
由2对括号,可以组成两种合法括号序列:()()、(())。
由4对括号组成的合法括号序列一共有多少种?
答案提交
这是一道结果填空的题,你只需要算出结果后提交即可。本题的结果为一个整数,在提交答案时只填写这个整数,填写多余的内容将无法得分。
答案 :14
编程题1 凯撒密码加密
问题描述
给定一个单词,请使用凯撒密码将这个单词加密。
凯撒密码是一种替换加密的技术,单词中的所有字母都在字母表上向后偏移3位后被替换成密文。即a变为d,b变为e,…,w变为z,x变为a,y变为b,z变为c。
例如,lanqiao会变成odqtldr。
输入格式
输入一行,包含一个单词,单词中只包含小写英文字母。
输出格式
输出一行,表示加密后的密文。
样例输入
lanqiao
样例输出
odqtldr
评测用例规模与约定
对于所有评测用例,单词中的字母个数不超过1001
2
3
4
5
6
7
8
9
10ans = ""
strq = list(input())
for i in range(len(strq)):
if 97 <= ord(strq[i]) <= 119:
strq[i] = chr(ord(strq[i]) + 3)
else:
strq[i] = chr(ord(strq[i]) - 120 + 97)
for i in range(len(strq)):
ans += strq[i]
print(ans)
编程题2 反倍数
问题描述
给定三个整数 a, b, c,如果一个整数既不是 a 的整数倍也不是 b 的整数倍还不是 c 的整数倍,则这个数称为反倍数。
请问在 1 至 n 中有多少个反倍数。
输入格式
输入的第一行包含一个整数 n。
第二行包含三个整数 a, b, c,相邻两个数之间用一个空格分隔。
输出格式
输出一行包含一个整数,表示答案。
样例输入
30
2 3 6
样例输出
10
样例说明
以下这些数满足要求:1, 5, 7, 11, 13, 17, 19, 23, 25, 29。
评测用例规模与约定
对于 40% 的评测用例,1 <= n <= 10000。
对于 80% 的评测用例,1 <= n <= 100000。
对于所有评测用例,1 <= n <= 1000000,1 <= a <= n,1 <= b <= n,1 <= c <= n。
1 | n = int(input()) |
编程题3 摆动序列
问题描述
如果一个序列的奇数项都比前一项大,偶数项都比前一项小,则称为一个摆动序列。即 a[2i]<a[2i-1], a[2i+1]>a[2i]。
小明想知道,长度为 m,每个数都是 1 到 n 之间的正整数的摆动序列一共有多少个。
输入格式
输入一行包含两个整数 m,n。
输出格式
输出一个整数,表示答案。答案可能很大,请输出答案除以10000的余数。
样例输入
3 4
样例输出
14
样例说明
以下是符合要求的摆动序列:
2 1 2
2 1 3
2 1 4
3 1 2
3 1 3
3 1 4
3 2 3
3 2 4
4 1 2
4 1 3
4 1 4
4 2 3
4 2 4
4 3 4
评测用例规模与约定
对于 20% 的评测用例,1 <= n, m <= 5;
对于 50% 的评测用例,1 <= n, m <= 10;
对于 80% 的评测用例,1 <= n, m <= 100;
对于所有评测用例,1 <= n, m <= 1000。
1 | ans = 0 |
编程题4 螺旋矩阵
问题描述
对于一个 n 行 m 列的表格,我们可以使用螺旋的方式给表格依次填上正整数,我们称填好的表格为一个螺旋矩阵。
例如,一个 4 行 5 列的螺旋矩阵如下:
1 2 3 4 5
14 15 16 17 6
13 20 19 18 7
12 11 10 9 8
输入格式
输入的第一行包含两个整数 n, m,分别表示螺旋矩阵的行数和列数。
第二行包含两个整数 r, c,表示要求的行号和列号。
输出格式
输出一个整数,表示螺旋矩阵中第 r 行第 c 列的元素的值。
样例输入
4 5
2 2
样例输出
15
评测用例规模与约定
对于 30% 的评测用例,2 <= n, m <= 20。
对于 70% 的评测用例,2 <= n, m <= 100。
对于所有评测用例,2 <= n, m <= 1000,1 <= r <= n,1 <= c <= m。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44n, m = map(int, input().split())
r, c = map(int, input().split())
ansList = [[0 for _ in range(m)] for _ in range(n)]
vis = [[0 for _ in range(m)] for _ in range(n)]
i = 1
x = 0 # 当前纵坐标
y = 0 # 当前横坐标
while i < n * m:
while y < m and vis[x][y] == 0:
ansList[x][y] = i
vis[x][y] = 1
i += 1
y += 1
y -= 1
x += 1
while x < n and vis[x][y] == 0:
ansList[x][y] = i
vis[x][y] = 1
i += 1
x += 1
x -= 1
y -= 1
while y >= 0 and vis[x][y] == 0:
ansList[x][y] = i
vis[x][y] = 1
i += 1
y -= 1
y += 1
x -= 1
while x >= 0 and vis[x][y] == 0:
ansList[x][y] = i
vis[x][y] = 1
i += 1
x -= 1
x += 1
y += 1
print(ansList[r-1][c-1])
编程题5 村庄通电
问题描述
2015年,全中国实现了户户通电。作为一名电力建设者,小明正在帮助一带一路上的国家通电。
这一次,小明要帮助 n 个村庄通电,其中 1 号村庄正好可以建立一个发电站,所发的电足够所有村庄使用。
现在,这 n 个村庄之间都没有电线相连,小明主要要做的是架设电线连接这些村庄,使得所有村庄都直接或间接的与发电站相通。
小明测量了所有村庄的位置(坐标)和高度,如果要连接两个村庄,小明需要花费两个村庄之间的坐标距离加上高度差的平方,形式化描述为坐标为 (x_1, y_1) 高度为 h_1 的村庄与坐标为 (x_2, y_2) 高度为 h_2 的村庄之间连接的费用为
sqrt((x_1-x_2)(x_1-x_2)+(y_1-y_2)(y_1-y_2))+(h_1-h_2)*(h_1-h_2)。
在上式中 sqrt 表示取括号内的平方根。请注意括号的位置,高度的计算方式与横纵坐标的计算方式不同。
由于经费有限,请帮助小明计算他至少要花费多少费用才能使这 n 个村庄都通电。
输入格式
输入的第一行包含一个整数 n ,表示村庄的数量。
接下来 n 行,每个三个整数 x, y, h,分别表示一个村庄的横、纵坐标和高度,其中第一个村庄可以建立发电站。
输出格式
输出一行,包含一个实数,四舍五入保留 2 位小数,表示答案。
样例输入
4
1 1 3
9 9 7
8 8 6
4 5 4
样例输出
17.41
评测用例规模与约定
对于 30% 的评测用例,1 <= n <= 10;
对于 60% 的评测用例,1 <= n <= 100;
对于所有评测用例,1 <= n <= 1000,0 <= x, y, h <= 10000。
1 |
编程题6 小明植树
问题描述
小明和朋友们一起去郊外植树,他们带了一些在自己实验室精心研究出的小树苗。
小明和朋友们一共有 n 个人,他们经过精心挑选,在一块空地上每个人挑选了一个适合植树的位置,总共 n 个。他们准备把自己带的树苗都植下去。
然而,他们遇到了一个困难:有的树苗比较大,而有的位置挨太近,导致两棵树植下去后会撞在一起。
他们将树看成一个圆,圆心在他们找的位置上。如果两棵树对应的圆相交,这两棵树就不适合同时植下(相切不受影响),称为两棵树冲突。
小明和朋友们决定先合计合计,只将其中的一部分树植下去,保证没有互相冲突的树。他们同时希望这些树所能覆盖的面积和(圆面积和)最大。
输入格式
输入的第一行包含一个整数 n ,表示人数,即准备植树的位置数。
接下来 n 行,每行三个整数 x, y, r,表示一棵树在空地上的横、纵坐标和半径。
输出格式
输出一行包含一个整数,表示在不冲突下可以植树的面积和。由于每棵树的面积都是圆周率的整数倍,请输出答案除以圆周率后的值(应当是一个整数)。
样例输入
6
1 1 2
1 4 2
1 7 2
4 1 2
4 4 2
4 7 2
样例输出
12
评测用例规模与约定
对于 30% 的评测用例,1 <= n <= 10;
对于 60% 的评测用例,1 <= n <= 20;
对于所有评测用例,1 <= n <= 30,0 <= x, y <= 1000,1 <= r <= 1000。
1 | def isTure(i): |
网站架构
基于Docker容器里构建高并发网站
拓扑图: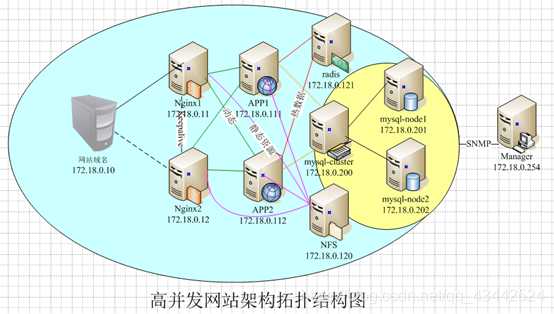
上文讲述了简单的基于Docker的配置Nginx反向代理和负载均衡
本文讲述Keepalived与Nginx共同实现高可用实例
|IP地址 | 容器名 |功能|
|–|–|–|
| 172.18.0.11| nginx1| nginx+keepalived |
| 172.18.0.12|nginx2| nginx+keepalived |
| 172.18.0.10|VIP| |
安装配置keepalived
使用nginx镜像生成nginx-keep镜像
1) 启动nginx容器并进入docker run -d --privileged nginx /usr/sbin/init
2) 在nginx容器中使用yum方式安装keepalivedyum install -y keepalived
3) 保存容器为镜像docker commit 容器ID nginx-keep
使用nginx-keep镜像启动nginx1和nginx2两个容器
1) 创建docker网络
docker network create --subnet=172.18.0.0/16 cluster
2) 查看宿主机上的docker网络类型种类docker network ls
3) 启动容器nginx1,设定地址为172.18.0.11docker run -d --privileged --net cluster --ip 172.18.0.11 --name nginx1 nginx-keep /usr/sbin/init
4) 启动容器nginx2,设定地址为172.18.0.12docker run -d --privileged --net cluster --ip 172.18.0.12 --name nginx2 nginx-keep /usr/sbin/init
5) 配置容器nginx1, nginx2的web服务,编辑首页内容为“nginx1”,“nginx2”, 在宿主机访问
1
2
3
4
5
6[root@localhost ~]# curl 172.18.0.12
nginx2
[root@localhost ~]# curl 172.18.0.11
nginx1
[root@localhost ~]#
在nginx1和nginx2两个容器配置keepalived
1) 在nginx1编辑 /etc/keepalived/keepalived.conf ,启动keepalived服务
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33 ! Configuration File for keepalived
global_defs {
notification_email {
[email protected]
[email protected]
[email protected]
}
notification_email_from [email protected]
smtp_server 192.168.200.1
smtp_connect_timeout 30
router_id nginx1
vrrp_skip_check_adv_addr
#vrrp_strict
vrrp_garp_interval 0
vrrp_gna_interval 0
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
172.18.0.10
}
}
2) 在nginx2编辑 /etc/keepalived/keepalived.conf ,启动keepalived服务
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32 ! Configuration File for keepalived
global_defs {
notification_email {
[email protected]
[email protected]
[email protected]
}
notification_email_from [email protected]
smtp_server 192.168.200.1
smtp_connect_timeout 30
router_id nginx2
vrrp_skip_check_adv_addr
#vrrp_strict
vrrp_garp_interval 0
vrrp_gna_interval 0
}
vrrp_instance VI_1 {
state BACKUP
interface eth0
virtual_router_id 51
priority 90
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
172.18.0.10
}
}
注意:
在 /etc/keepalived/keepalived.conf配置文件中将#vrrp_strict注释掉, 否则会出现ping VIP不通的现象1
2
3
4
5
6vrrp_strict
#严格遵守VRRP协议。 这将禁止:
0 VIPs
unicast peers (单播对等体)
IPv6 addresses in VRRP version 2(VRRP版本2中的IPv6地址)
即vrrp_strict:严格遵守VRRP协议。下列情况将会阻止启动Keepalived:1. 没有VIP地址。2. 单播邻居。3. 在VRRP版本2中有IPv6地址。
3) 在宿主机使用浏览器访问虚拟地址curl http:// 172.18.0.101
2[root@localhost ~]# curl 172.18.0.10
nginx1
4) 在nginx1上当掉网卡ifconfig eth0 down
5) 在宿主机使用浏览器访问虚拟地址curl http:// 172.18.0.10
1
2[root@localhost ~]# curl 172.18.0.10
nginx2
配置keepalived 支持nginx高可用
编写 Nginx 状态检测脚本
1) 在nginx1上编写 Nginx 状态检测脚本/etc/keepalived/nginx_check.sh
1 |
|
脚本说明: 当检测nginx没有进程时选择启动nginx, 如果启动失败则关闭keepalived
2) 赋予/etc/keepalived/nginx_check.sh执行权限
chmod a+x /etc/keepalived/nginx_check.sh
配置keepalived 支持nginx高可用
1) 在nginx1上编辑/etc/keepalived/keepalived.conf
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39! Configuration File for keepalived
global_defs {
notification_email {
[email protected]
[email protected]
[email protected]
}
notification_email_from [email protected]
smtp_server 192.168.200.1
smtp_connect_timeout 30
router_id nginx1
vrrp_skip_check_adv_addr
#vrrp_strict
vrrp_garp_interval 0
vrrp_gna_interval 0
}
vrrp_script chk_nginx{
script "/etc/keepalived/nginx_check.sh"
interval 2
weight -20
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
track_script{
chk_nginx
}
virtual_ipaddress {
172.18.0.10
}
}
2) 重新启动keepalived,在主机使用浏览器访问虚拟地址
1
2[root@localhost ~]# curl 172.18.0.10
nginx1
3) 在nginx1停止nginx服务,在主机使用浏览器访问虚拟地址
1
2[root@localhost ~]# curl 172.18.0.10
nginx2
]]>原因: weight -20 每当运行一次vrrp_script chk_nginx脚本, 本机的权重减20
记一次部署Flannel网络后网络不通问题, 查询网上资料无果
自己记录一下解决过程
现象
1 | [root@k8s-master01 ~]# kubectl get pod -n kube-system |
1 | [root@k8s-master01 ~]# kubectl get node |
由以上可以看到我部署Flannel以后, master检测到node节点 并且flannel容器显示Running正常
排查问题
1 | [root@k8s-master01 ~]# ip a |
6: flannel.1网络没有ip信息, 并且显示DOWN的状态
1 | [root@k8s-master01 flannel]# ping 10.244.2.6 |
1 | [root@k8s-node01 ~]# ping 10.244.2.6 |
1 | [root@k8s-node02 ~]# ping 10.244.2.6 |
一个存在与node2的pod只有node2能ping 通, 其他节点全部超时
解决
方法1
1 | [root@k8s-node01 ~]# sudo iptables -P INPUT ACCEPT |
清理IPTABLES规则, 保存
问题没有解决 使用方法二
方法2
卸载flannel网络1
2
3
4
5
6
7
8
9
10#第一步,在master节点删除flannel
kubectl delete -f kube-flannel.yml
#第二步,在node节点清理flannel网络留下的文件
ifconfig cni0 down
ip link delete cni0
ifconfig flannel.1 down
ip link delete flannel.1
rm -rf /var/lib/cni/
rm -f /etc/cni/net.d/*
重新部署Flannel网络1
2
3
4
5
6
7
8
9
10
11[root@k8s-master01 flannel]# kubectl create -f kube-flannel.yml
podsecuritypolicy.policy/psp.flannel.unprivileged created
clusterrole.rbac.authorization.k8s.io/flannel created
clusterrolebinding.rbac.authorization.k8s.io/flannel created
serviceaccount/flannel created
configmap/kube-flannel-cfg created
daemonset.apps/kube-flannel-ds-amd64 created
daemonset.apps/kube-flannel-ds-arm64 created
daemonset.apps/kube-flannel-ds-arm created
daemonset.apps/kube-flannel-ds-ppc64le created
daemonset.apps/kube-flannel-ds-s390x created
1 | [root@k8s-master01 flannel]# kubectl get pod -n kube-system |
重新部署Flannel网络后 容器需要重置, 删除就可以 k8s会重新自动添加1
2
3
4
5
6[root@k8s-master01 flannel]# ping 10.244.1.2
PING 10.244.1.2 (10.244.1.2) 56(84) bytes of data.
64 bytes from 10.244.1.2: icmp_seq=1 ttl=63 time=1.04 ms
64 bytes from 10.244.1.2: icmp_seq=2 ttl=63 time=0.498 ms
64 bytes from 10.244.1.2: icmp_seq=3 ttl=63 time=0.575 ms
64 bytes from 10.244.1.2: icmp_seq=4 ttl=63 time=0.578 ms
1 | [root@k8s-node01 ~]# ping 10.244.1.2 |
1 | [root@k8s-node02 ~]# ping 10.244.1.2 |
1 | [root@k8s-master01 flannel]# ifconfig |
flannel网络显示正常, 容器之间可以跨主机互通!
]]>上节讲解了通过kubeadm 搭建集群kubeadm1.15.1环境,现在的集群已经搭建成功了,今天给大家展示Kubernetes Dashboard 插件的安装
下载官方的yaml文件
进入官网:https://kubernetes.io/docs/tasks/access-application-cluster/web-ui-dashboard/1
$ wget https://raw.githubusercontent.com/kubernetes/dashboard/v1.10.1/src/deploy/recommended/kubernetes-dashboard.yaml
修改:
type,指定端口类型为 NodePort,这样外界可以通过地址 nodeIP:nodePort 访问 dashboard
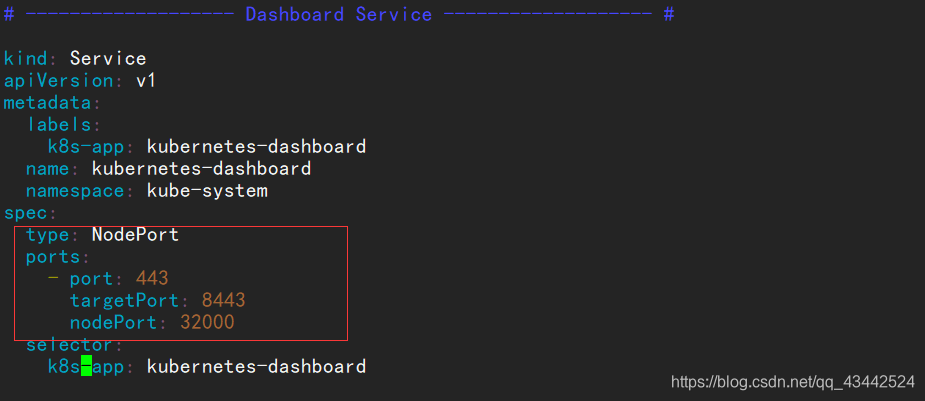
如果网络不好,不能直接下载,需要手动创建kubernetes-dashboard.yaml文件1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164# Copyright 2017 The Kubernetes Authors.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ------------------- Dashboard Secret ------------------- #
apiVersion: v1
kind: Secret
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard-certs
namespace: kube-system
type: Opaque
# ------------------- Dashboard Service Account ------------------- #
apiVersion: v1
kind: ServiceAccount
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kube-system
# ------------------- Dashboard Role & Role Binding ------------------- #
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: kubernetes-dashboard-minimal
namespace: kube-system
rules:
# Allow Dashboard to create 'kubernetes-dashboard-key-holder' secret.
- apiGroups: [""]
resources: ["secrets"]
verbs: ["create"]
# Allow Dashboard to create 'kubernetes-dashboard-settings' config map.
- apiGroups: [""]
resources: ["configmaps"]
verbs: ["create"]
# Allow Dashboard to get, update and delete Dashboard exclusive secrets.
- apiGroups: [""]
resources: ["secrets"]
resourceNames: ["kubernetes-dashboard-key-holder", "kubernetes-dashboard-certs"]
verbs: ["get", "update", "delete"]
# Allow Dashboard to get and update 'kubernetes-dashboard-settings' config map.
- apiGroups: [""]
resources: ["configmaps"]
resourceNames: ["kubernetes-dashboard-settings"]
verbs: ["get", "update"]
# Allow Dashboard to get metrics from heapster.
- apiGroups: [""]
resources: ["services"]
resourceNames: ["heapster"]
verbs: ["proxy"]
- apiGroups: [""]
resources: ["services/proxy"]
resourceNames: ["heapster", "http:heapster:", "https:heapster:"]
verbs: ["get"]
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: kubernetes-dashboard-minimal
namespace: kube-system
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: kubernetes-dashboard-minimal
subjects:
- kind: ServiceAccount
name: kubernetes-dashboard
namespace: kube-system
# ------------------- Dashboard Deployment ------------------- #
kind: Deployment
apiVersion: apps/v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kube-system
spec:
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
k8s-app: kubernetes-dashboard
template:
metadata:
labels:
k8s-app: kubernetes-dashboard
spec:
containers:
- name: kubernetes-dashboard
image: k8s.gcr.io/kubernetes-dashboard-amd64:v1.10.1
ports:
- containerPort: 8443
protocol: TCP
args:
- --auto-generate-certificates
# Uncomment the following line to manually specify Kubernetes API server Host
# If not specified, Dashboard will attempt to auto discover the API server and connect
# to it. Uncomment only if the default does not work.
# - --apiserver-host=http://my-address:port
volumeMounts:
- name: kubernetes-dashboard-certs
mountPath: /certs
# Create on-disk volume to store exec logs
- mountPath: /tmp
name: tmp-volume
livenessProbe:
httpGet:
scheme: HTTPS
path: /
port: 8443
initialDelaySeconds: 30
timeoutSeconds: 30
volumes:
- name: kubernetes-dashboard-certs
secret:
secretName: kubernetes-dashboard-certs
- name: tmp-volume
emptyDir: {}
serviceAccountName: kubernetes-dashboard
# Comment the following tolerations if Dashboard must not be deployed on master
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
# ------------------- Dashboard Service ------------------- #
kind: Service
apiVersion: v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kube-system
spec:
type: NodePort
ports:
- port: 443
targetPort: 8443
nodePort: 32000
selector:
k8s-app: kubernetes-dashboard
拉取镜像
为了避免访问外国网站,这里直接通过国内的阿里镜像拉取,通过tag更改名称1
2docker pull registry.cn-hangzhou.aliyuncs.com/rsqlh/kubernetes-dashboard:v1.10.1
docker tag registry.cn-hangzhou.aliyuncs.com/rsqlh/kubernetes-dashboard:v1.10.1 k8s.gcr.io/kubernetes-dashboard-amd64:v1.10.1
1 | [root@k8s-node01 ~]# docker pull registry.cn-hangzhou.aliyuncs.com/rsqlh/kubernetes-dashboard:v1.10.1 |
部署yaml文件
通过kubectl create -f命令部署1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23[root@k8s-master01 ui]# kubectl create -f kubernetes-dashboard.yaml
secret/kubernetes-dashboard-certs created
serviceaccount/kubernetes-dashboard created
role.rbac.authorization.k8s.io/kubernetes-dashboard-minimal created
rolebinding.rbac.authorization.k8s.io/kubernetes-dashboard-minimal created
deployment.apps/kubernetes-dashboard created
service/kubernetes-dashboard created
[root@k8s-master01 ui]# kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-5c98db65d4-54j5c 1/1 Running 0 3h53m
coredns-5c98db65d4-jmvbf 1/1 Running 0 3h53m
etcd-k8s-master01 1/1 Running 2 10d
kube-apiserver-k8s-master01 1/1 Running 2 10d
kube-controller-manager-k8s-master01 1/1 Running 3 10d
kube-flannel-ds-amd64-6h79p 1/1 Running 2 9d
kube-flannel-ds-amd64-bnvtd 1/1 Running 3 9d
kube-flannel-ds-amd64-bsq4j 1/1 Running 2 9d
kube-proxy-5fn9m 1/1 Running 1 9d
kube-proxy-6hjvp 1/1 Running 2 9d
kube-proxy-t47n9 1/1 Running 2 10d
kube-scheduler-k8s-master01 1/1 Running 4 10d
kubernetes-dashboard-7d75c474bb-zj9c6 1/1 Running 0 18s
[root@k8s-master01 ui]#
可以看到kubernetes-dashboard处于Running状态1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20[root@k8s-master01 ui]# kubectl get svc -n kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP 10d
kubernetes-dashboard NodePort 10.110.65.174 <none> 443:32000/TCP 11m
[root@k8s-master01 ui]# kubectl get pod -n kube-system -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
coredns-5c98db65d4-54j5c 1/1 Running 0 4h5m 10.244.2.5 k8s-node02 <none> <none>
coredns-5c98db65d4-jmvbf 1/1 Running 0 4h6m 10.244.1.5 k8s-node01 <none> <none>
etcd-k8s-master01 1/1 Running 2 10d 192.168.0.50 k8s-master01 <none> <none>
kube-apiserver-k8s-master01 1/1 Running 2 10d 192.168.0.50 k8s-master01 <none> <none>
kube-controller-manager-k8s-master01 1/1 Running 3 10d 192.168.0.50 k8s-master01 <none> <none>
kube-flannel-ds-amd64-6h79p 1/1 Running 2 9d 192.168.0.52 k8s-node02 <none> <none>
kube-flannel-ds-amd64-bnvtd 1/1 Running 3 9d 192.168.0.50 k8s-master01 <none> <none>
kube-flannel-ds-amd64-bsq4j 1/1 Running 2 9d 192.168.0.51 k8s-node01 <none> <none>
kube-proxy-5fn9m 1/1 Running 1 9d 192.168.0.51 k8s-node01 <none> <none>
kube-proxy-6hjvp 1/1 Running 2 9d 192.168.0.52 k8s-node02 <none> <none>
kube-proxy-t47n9 1/1 Running 2 10d 192.168.0.50 k8s-master01 <none> <none>
kube-scheduler-k8s-master01 1/1 Running 4 10d 192.168.0.50 k8s-master01 <none> <none>
kubernetes-dashboard-7d75c474bb-zj9c6 1/1 Running 0 13m 10.244.1.6 k8s-node02 <none> <none>
[root@k8s-master01 ui]#
可以看到kubernetes-dashboard暴露在node2上的32000端口
访问ui页面
https://192.168.0.52:32000/ 这是我node2的ip地址
建议使用firefox访问, Chrome访问会禁止不安全证书访问
Token令牌登录
- 创建serviceaccount
kubectl create serviceaccount dashboard-admin -n kube-system1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38[root@k8s-master01 ~]# kubectl create serviceaccount dashboard-admin -n kube-system
serviceaccount/dashboard-admin created
[root@k8s-master01 ~]# kubectl get sa -n kube-system
NAME SECRETS AGE
attachdetach-controller 1 10d
bootstrap-signer 1 10d
certificate-controller 1 10d
clusterrole-aggregation-controller 1 10d
coredns 1 10d
cronjob-controller 1 10d
daemon-set-controller 1 10d
dashboard-admin 1 27s
default 1 10d
deployment-controller 1 10d
disruption-controller 1 10d
endpoint-controller 1 10d
expand-controller 1 10d
flannel 1 10d
generic-garbage-collector 1 10d
horizontal-pod-autoscaler 1 10d
job-controller 1 10d
kube-proxy 1 10d
kubernetes-dashboard 1 48m
namespace-controller 1 10d
node-controller 1 10d
persistent-volume-binder 1 10d
pod-garbage-collector 1 10d
pv-protection-controller 1 10d
pvc-protection-controller 1 10d
replicaset-controller 1 10d
replication-controller 1 10d
resourcequota-controller 1 10d
service-account-controller 1 10d
service-controller 1 10d
statefulset-controller 1 10d
token-cleaner 1 10d
ttl-controller 1 10d
[root@k8s-master01 ~]#
dashboard-admin 1 27s创建成功
- 把serviceaccount绑定在clusteradmin,授权serviceaccount用户具有整个集群的访问管理权限
1
kubectl create clusterrolebinding dashboard-cluster-admin --clusterrole=cluster-admin --serviceaccount=kube-system:dashboard-admin
1 | [root@k8s-master01 ~]# kubectl create clusterrolebinding dashboard-cluster-admin --clusterrole=cluster-admin --serviceaccount=kube-system:dashboard-admin |
- 获取serviceaccount的secret信息,可得到token(令牌)的信息
kubectl get secret -n kube-system
dashboard-admin-token-slfcr 通过上边命令获取到的kubectl describe secret dashboard-admin-token-slfcr -n kube-system1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53```bash
[root@k8s-master01 ~]# kubectl get secret -n kube-system
NAME TYPE DATA AGE
attachdetach-controller-token-j5vtc kubernetes.io/service-account-token 3 10d
bootstrap-signer-token-prjr2 kubernetes.io/service-account-token 3 10d
certificate-controller-token-f8rjx kubernetes.io/service-account-token 3 10d
clusterrole-aggregation-controller-token-l6lqh kubernetes.io/service-account-token 3 10d
coredns-token-p5z2z kubernetes.io/service-account-token 3 10d
cronjob-controller-token-jsp8k kubernetes.io/service-account-token 3 10d
daemon-set-controller-token-4fh89 kubernetes.io/service-account-token 3 10d
dashboard-admin-token-dl8pf kubernetes.io/service-account-token 3 9m2s
default-token-22jpc kubernetes.io/service-account-token 3 10d
deployment-controller-token-jc4xc kubernetes.io/service-account-token 3 10d
disruption-controller-token-p85cv kubernetes.io/service-account-token 3 10d
endpoint-controller-token-dhk4f kubernetes.io/service-account-token 3 10d
expand-controller-token-lbsrj kubernetes.io/service-account-token 3 10d
flannel-token-qjgks kubernetes.io/service-account-token 3 10d
generic-garbage-collector-token-6fwmg kubernetes.io/service-account-token 3 10d
horizontal-pod-autoscaler-token-vl8dh kubernetes.io/service-account-token 3 10d
job-controller-token-c2sfm kubernetes.io/service-account-token 3 10d
kube-proxy-token-qg465 kubernetes.io/service-account-token 3 10d
kubernetes-dashboard-certs NodePort 0 56m
kubernetes-dashboard-key-holder Opaque 2 56m
kubernetes-dashboard-token-hpg2q kubernetes.io/service-account-token 3 56m
namespace-controller-token-vvbxk kubernetes.io/service-account-token 3 10d
node-controller-token-5hmv6 kubernetes.io/service-account-token 3 10d
persistent-volume-binder-token-6vrk6 kubernetes.io/service-account-token 3 10d
pod-garbage-collector-token-f8bvl kubernetes.io/service-account-token 3 10d
pv-protection-controller-token-pp8bh kubernetes.io/service-account-token 3 10d
pvc-protection-controller-token-jf6lj kubernetes.io/service-account-token 3 10d
replicaset-controller-token-twbw8 kubernetes.io/service-account-token 3 10d
replication-controller-token-lr45r kubernetes.io/service-account-token 3 10d
resourcequota-controller-token-qlgbb kubernetes.io/service-account-token 3 10d
service-account-controller-token-bsqlq kubernetes.io/service-account-token 3 10d
service-controller-token-g6lvs kubernetes.io/service-account-token 3 10d
statefulset-controller-token-h6wrx kubernetes.io/service-account-token 3 10d
token-cleaner-token-wvwbn kubernetes.io/service-account-token 3 10d
ttl-controller-token-z2fm7 kubernetes.io/service-account-token 3 10d
[root@k8s-master01 ~]# kubectl describe secret dashboard-admin-token-dl8pf -n kube-system
Name: dashboard-admin-token-dl8pf
Namespace: kube-system
Labels: <none>
Annotations: kubernetes.io/service-account.name: dashboard-admin
kubernetes.io/service-account.uid: b4fc67f6-1cab-4486-8652-05346c939c6d
Type: kubernetes.io/service-account-token
Data
====
ca.crt: 1025 bytes
namespace: 11 bytes
token: eyJhbGciOiJSUzI1NiIsImtpZCI6IiJ9.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlLXN5c3RlbSIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJkYXNoYm9hcmQtYWRtaW4tdG9rZW4tZGw4cGYiLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC5uYW1lIjoiZGFzaGJvYXJkLWFkbWluIiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZXJ2aWNlLWFjY291bnQudWlkIjoiYjRmYzY3ZjYtMWNhYi00NDg2LTg2NTItMDUzNDZjOTM5YzZkIiwic3ViIjoic3lzdGVtOnNlcnZpY2VhY2NvdW50Omt1YmUtc3lzdGVtOmRhc2hib2FyZC1hZG1pbiJ9.ArAKoKEiZ0xaV9rqff63iq2t6iAsWBmA-VhHKK_pnkiMObpPL-JjZras40HO0crE7Gnou9dUWCStW3AbfmtJ1SX_Hmo4OlXGH2xFBJ-_2wruwWOU89dlHhOnhw8__skhsVrE92-KDK00GRSrA4BkUu8PWp45jCQyIwFbF8h3L2ydcNlcs_rxGieVFRc1p9gaf_HAyXIIHEgu-M5LxA6BduN-3Z7WBzYMokFd_r_c_beAQ4CUlTYc1c0FjmqLeyZpyLJL6IMqztjaYHFXiRty6c-PQHZd6HQoElJShbw1lhZtHXSSw0A70Kb3ZVfqQZxRaOsqJYo70sZXQQRaYso6fg
[root@k8s-master01 ~]#
输入Token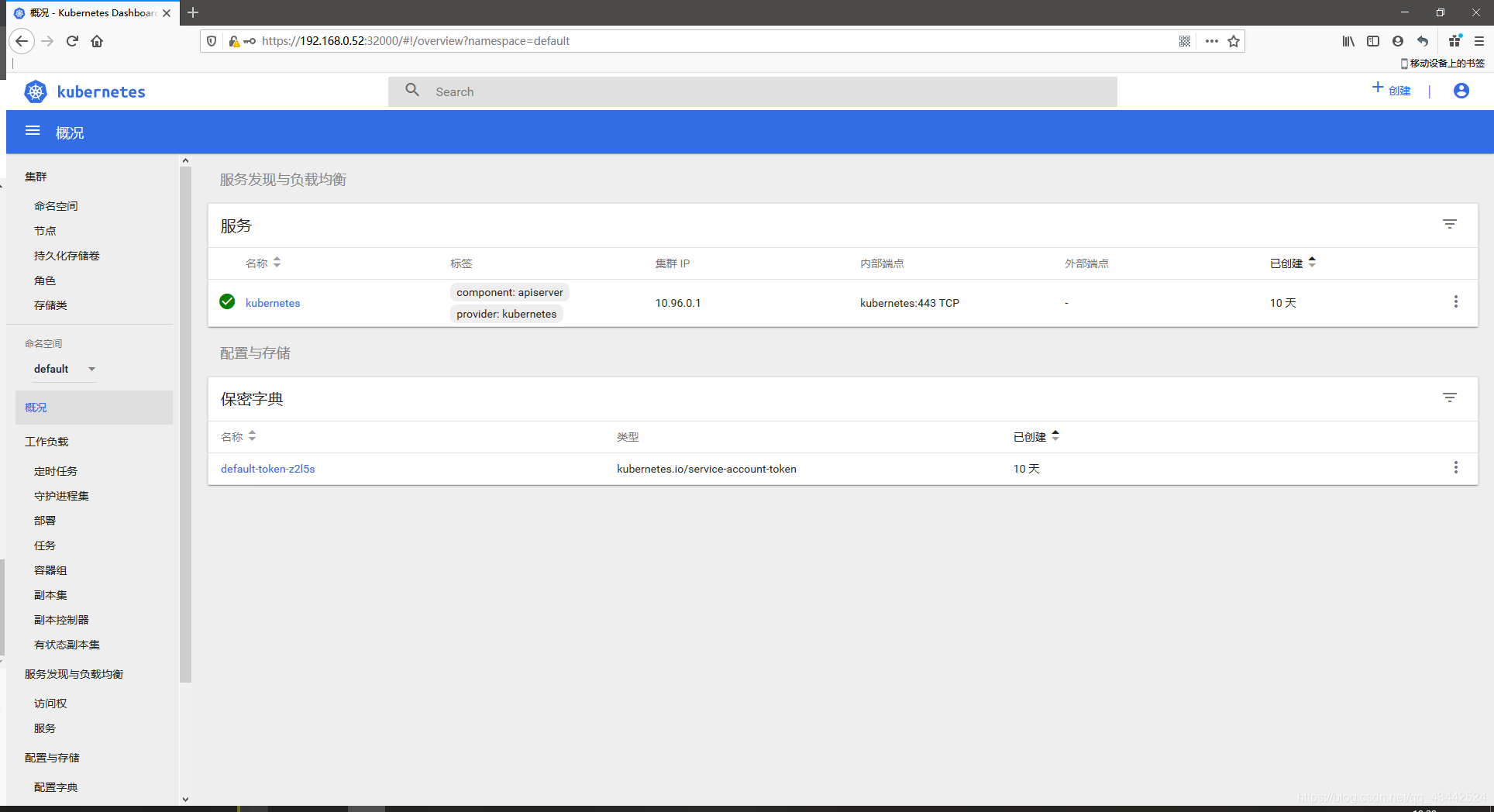
部署成功!
今天在使用K8s查看pod时发现,coredns出现了CrashLoopBackOff1
2
3
4
5
6
7
8
9
10
11
12
13
14[root@k8s-master01 flannel]# kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-5c98db65d4-f9rb7 0/1 CrashLoopBackOff 50 9d
coredns-5c98db65d4-xcd9s 0/1 CrashLoopBackOff 50 9d
etcd-k8s-master01 1/1 Running 2 9d
kube-apiserver-k8s-master01 1/1 Running 2 9d
kube-controller-manager-k8s-master01 1/1 Running 3 9d
kube-flannel-ds-amd64-6h79p 1/1 Running 2 9d
kube-flannel-ds-amd64-bnvtd 1/1 Running 3 9d
kube-flannel-ds-amd64-bsq4j 1/1 Running 2 9d
kube-proxy-5fn9m 1/1 Running 1 9d
kube-proxy-6hjvp 1/1 Running 2 9d
kube-proxy-t47n9 1/1 Running 2 9d
kube-scheduler-k8s-master01 1/1 Running 4 9d
使用kubectl logs命令查看, 报错很奇怪1
2
3[root@k8s-master01 ~]# kubectl logs coredns-5c98db65d4-xcd9s -n kube-system
E0413 06:32:09.919666 1 reflector.go:134] github.com/coredns/coredns/plugin/kubernetes/controller.go:317: Failed to list *v1.Endpoints: Get https://10.96.0.1:443/api/v1/endpoints?limit=500&resourceVersion=0: dial tcp 10.96.0.1:443: connect: no route to host
E0413 06:32:09.919666 1 reflector.go:134] github.com/coredns/coredns/plugin/kubernetes/controller.go:317: Failed to list *v1.Endpoints: Get https://10.96.0.1:443/api/v1/endpoints?limit=500&resourceVersion=0: dial tcp 10.96.0.1:443: connect: no route to host
原因:
查阅k8s官方文档1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16coredns pods 有 CrashLoopBackOff 或者 Error 状态
如果有些节点运行的是旧版本的 Docker,同时启用了 SELinux,您或许会遇到 coredns pods 无法启动的情况。 要解决此问题,您可以尝试以下选项之一:
升级到 Docker 的较新版本。
禁用 SELinux.
修改 coredns 部署以设置 allowPrivilegeEscalation 为 true:
kubectl -n kube-system get deployment coredns -o yaml | \
sed 's/allowPrivilegeEscalation: false/allowPrivilegeEscalation: true/g' | \
kubectl apply -f -
CoreDNS 处于 CrashLoopBackOff 时的另一个原因是当 Kubernetes 中部署的 CoreDNS Pod 检测 到环路时。有许多解决方法 可以避免在每次 CoreDNS 监测到循环并退出时,Kubernetes 尝试重启 CoreDNS Pod 的情况。
警告:
警告:禁用 SELinux 或设置 allowPrivilegeEscalation 为 true 可能会损害集群的安全性。
我这里的原因可能是以前配置iptables时产生的
解决
- 设置iptables为空规则
iptables -F && service iptables save - 删除报错的coredns pod
1
2
3
4
5
6[root@k8s-master01 flannel]# kubectl delete pod coredns-5c98db65d4-xcd9s
Error from server (NotFound): pods "coredns-5c98db65d4-xcd9s" not found
[root@k8s-master01 flannel]# kubectl delete pod coredns-5c98db65d4-xcd9s -n kube-system
pod "coredns-5c98db65d4-xcd9s" deleted
[root@k8s-master01 flannel]# kubectl delete pod coredns-5c98db65d4-f9rb7 -n kube-system
pod "coredns-5c98db65d4-f9rb7" deleted
重新查看pod1
2
3
4
5
6
7
8
9
10
11
12
13
14
15[root@k8s-master01 flannel]# kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-5c98db65d4-54j5c 1/1 Running 0 13m
coredns-5c98db65d4-jmvbf 1/1 Running 0 14m
etcd-k8s-master01 1/1 Running 2 9d
kube-apiserver-k8s-master01 1/1 Running 2 9d
kube-controller-manager-k8s-master01 1/1 Running 3 9d
kube-flannel-ds-amd64-6h79p 1/1 Running 2 9d
kube-flannel-ds-amd64-bnvtd 1/1 Running 3 9d
kube-flannel-ds-amd64-bsq4j 1/1 Running 2 9d
kube-proxy-5fn9m 1/1 Running 1 9d
kube-proxy-6hjvp 1/1 Running 2 9d
kube-proxy-t47n9 1/1 Running 2 9d
kube-scheduler-k8s-master01 1/1 Running 4 9d
[root@k8s-master01 flannel]#
状态重新变成Running
目录
Kubernetes(K8s)入门到实践(一)—-Kubernetes入门
Kubernetes(K8s)入门到实践(二)—-Kubernetes的基本概念和术语
Kubernetes(K8s)入门到实践(三)—-Kubernetes Centos7集群安装
Kubernetes(K8s)入门到实践(四)—-Kubernetes1.15.1配置私有仓库Harbor
前期准备
- 需要三台K8s节点
- Harbor虚拟机
- docker-compose
- harbor安装包
安装docker
1 | yum install -y yum-utils device-mapper-persistent-data lvm2 |
安装完成后需要建立/etc/docker/daemon.json文件1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18# 启动docker
systemctl start docker && systemctl enable docker
## 创建 /etc/docker 目录
mkdir /etc/docker
# 配置 daemon.json
vim /etc/docker/daemon.json
{
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
},
"insecure-registries": ["https://hub.test.com"]
}
mkdir -p /etc/systemd/system/docker.service.d
# 重启docker服务
systemctl daemon-reload && systemctl restart docker && systemctl enable docker
同理: K8s节点也需要一样修改/etc/docker/daemon.json文件
安装Harbor
下载docker-compose
1 | curl -L https://github.com/docker/compose/releases/download/1.9.0/docker-compose-`uname -s`-`uname -m`> ./docker-compose |
下载解压Harbor
Harbor 官方地址:https://github.com/vmware/harbor/releases1
2
3
4
5[root@localhost ~]# chmod a+x docker-compose
[root@localhost ~]# mv docker-compose /usr/local/bin/
[root@localhost ~]# tar -zxvf harbor-offline-installer-v1.2.0.tgz
[root@localhost ~]# mv harbor /usr/local/
[root@localhost ~]# cd /usr/local/harbor/
配置harbor.cfg
修改为https协议,并且定义网址1
2hostname = hub.test.com
ui_url_protocol = https
以下为ssl证书配置文件目录 接下来配置HTTPS证书1
2
3
4
5ssl_cert = /data/cert/server.crt
ssl_cert_key = /data/cert/server.key
#The path of secretkey storage
secretkey_path = /data
创建https证书以及配置相关目录权限
创建cert目录,输入密码例如123456下面配置会用到1
2
3
4
5
6
7
8
9[root@localhost harbor]# mkdir -p /data/cert
[root@localhost harbor]# cd /data/cert/
[root@localhost cert]# openssl genrsa -des3 -out server.key 2048
Generating RSA private key, 2048 bit long modulus
...................................+++
................+++
e is 65537 (0x10001)
Enter pass phrase for server.key:
Verifying - Enter pass phrase for server.key:
生成服务器CSR证书请求文件,注意站点名称要一致
输入刚才设置的密码进行配置
Common Name (eg, your name or your server’s hostname) []:
hub.test.com一定要填上面配置的网址
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
Enter pass phrase for server.key:
You are about to be asked to enter information that will be incorporated
into your certificate request.
What you are about to enter is what is called a Distinguished Name or a DN.
There are quite a few fields but you can leave some blank
For some fields there will be a default value,
If you enter '.', the field will be left blank.
-----
Country Name (2 letter code) [XX]:CN
State or Province Name (full name) []:Hebei
Locality Name (eg, city) [Default City]:sjz
Organization Name (eg, company) [Default Company Ltd]:test
Organizational Unit Name (eg, section) []:test
Common Name (eg, your name or your server's hostname) []:hub.test.com
Email Address []:[email protected]
Please enter the following 'extra' attributes
to be sent with your certificate request
A challenge password []:
An optional company name []:
生成服务器认证证书1
2
3
4
5
6
7
8
9
10
11
12
13[root@localhost cert]# cp server.key server.key.org
[root@localhost cert]# openssl rsa -in server.key.org -out server.key
Enter pass phrase for server.key.org:
writing RSA key
[root@localhost cert]# openssl x509 -req -days 365 -in server.csr -signkey server.key -out server.crt
Signature ok
subject=/C=CN/ST=Hebei/L=sjz/O=test/OU=test/CN=hub.test.com/emailAddress=test@qq.com
Getting Private key
[root@localhost cert]# ls
server.crt server.csr server.key server.key.org
[root@localhost cert]# chmod a+x *
[root@localhost cert]# cd -
/usr/local/harbor
安装1
2
3
4
5
6
7
8
9
10
11[root@localhost harbor]# ./install.sh
[root@localhost harbor]# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
c998c35434cd vmware/nginx-photon:1.11.13 "nginx -g 'daemon of…" 2 hours ago Up 2 hours 0.0.0.0:80->80/tcp, 0.0.0.0:443->443/tcp, 0.0.0.0:4443->4443/tcp nginx
b8651abbdc0f vmware/harbor-jobservice:v1.2.0 "/harbor/harbor_jobs…" 2 hours ago Up 2 hours harbor-jobservice
38cd42c3ad61 vmware/harbor-ui:v1.2.0 "/harbor/harbor_ui" 2 hours ago Up 2 hours harbor-ui
7117305239e4 vmware/harbor-adminserver:v1.2.0 "/harbor/harbor_admi…" 2 hours ago Up 2 hours harbor-adminserver
547244f64e7b vmware/harbor-db:v1.2.0 "docker-entrypoint.s…" 2 hours ago Up 2 hours 3306/tcp harbor-db
08ac3fe587c8 vmware/registry:2.6.2-photon "/entrypoint.sh serv…" 2 hours ago Up 2 hours 5000/tcp registry
a137bc1e2548 vmware/harbor-log:v1.2.0 "/bin/sh -c 'crond &…" 2 hours ago Up 2 hours 127.0.0.1:1514->514/tcp harbor-log
[root@localhost harbor]#
修改hosts文件映射
修改k8s节点与Harbor虚拟机/etc/hosts文件1
2
3
4192.168.0.50 k8s-master01
192.168.0.51 k8s-node01
192.168.0.52 k8s-node02
192.168.0.44 hub.test.com
本地hosts文件添加1
192.168.0.44 hub.test.com
登录账号admin,密码Harbor12345
Harbor上传镜像
拉取镜像
这是是从我的docker hub中拉取的镜像plutoacharon/myapp:v1,也可以从docker hub中搜索拉取想要上传的镜像docker pull plutoacharon/myapp:v11
2
3
4
5
6
7
8
9
10
11
12
13
14
15[root@localhost ~]# docker pull plutoacharon/myapp:v1
v1: Pulling from plutoacharon/myapp
550fe1bea624: Pull complete
af3988949040: Pull complete
d6642feac728: Pull complete
c20f0a205eaa: Pull complete
fe78b5db7c4e: Pull complete
6565e38e67fe: Pull complete
Digest: sha256:9c3dc30b5219788b2b8a4b065f548b922a34479577befb54b03330999d30d513
Status: Downloaded newer image for plutoacharon/myapp:v1
docker.io/plutoacharon/myapp:v1
[root@localhost ~]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
plutoacharon/myapp v1 d4a5e0eaa84f 2 years ago 15.5MB
[root@localhost ~]#
上传镜像
首先使用docker login https://hub.test.com登录才可以上传到Harbor中1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18[root@localhost ~]# docker login https://hub.test.com
Username: admin
Password:
WARNING! Your password will be stored unencrypted in /root/.docker/config.json.
Configure a credential helper to remove this warning. See
https://docs.docker.com/engine/reference/commandline/login/#credentials-store
Login Succeeded
[root@localhost ~]# docker tag plutoacharon/myapp:v1 hub.test.com/library/myapp:v1
[root@localhost ~]# docker push hub.test.com/library/myapp:v1
The push refers to repository [hub.test.com/library/myapp]
a0d2c4392b06: Pushed
05a9e65e2d53: Pushed
68695a6cfd7d: Pushed
c1dc81a64903: Pushed
8460a579ab63: Pushed
d39d92664027: Pushed
v1: digest: sha256:9eeca44ba2d410e54fccc54cbe9c021802aa8b9836a0bcf3d3229354e4c8870e size: 1569
Kubernetes拉取运行Harbor镜像
1 | [root@k8s-master01 ~]# kubectl run nginx-deployment --image=hub.test.com/library/myapp:v1 --port=80 --replicas=1 |
kubectl get pod -o wide可以看到nginx-deployment在node1上运行1
2
3
4[root@k8s-node01 ~]# docker ps | grep nginx
066e82c78200 hub.test.com/library/myapp "nginx -g 'daemon of…" 20 minutes ago Up 20 minutes k8s_nginx-deployment_nginx-deployment-bdf84f685-pg7qk_default_11af7460-37a5-4d61-b94c-5c64684110ed_0
3a0c5624068c k8s.gcr.io/pause:3.1 "/pause" 20 minutes ago Up 20 minutes k8s_POD_nginx-deployment-bdf84f685-pg7qk_default_11af7460-37a5-4d61-b94c-5c64684110ed_0
[root@k8s-node01 ~]#
1 | [root@k8s-node01 ~]# curl 10.244.1.2 |
网站架构
基于Docker容器里构建高并发网站
拓扑图:
正向代理
- 代理:也被叫做正向代理,是一个位于客户端和目标服务器之间的代理服务器
- 作用:客户端将发送的请求和指定的目标服务器提交给代理服务器,然后代理服务器向目标服务器发起请求,并将获得的响应结果返回给客户端的过程
反向代理
- 反向代理:对于客户端而言就是目标服务器
- 作用:客户端向反向代理服务器发送请求后,反向代理服务器将该请求转发给内部网络上的后端服务器,并将从后端服务器上得到的响应结果返回给客户端
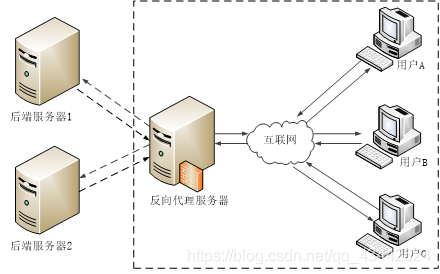
反向代理服务配置
- 反向代理的配置指令:proxy_pass,用于设置后端服务器的地址。该地址中包括传输数据使用的协议、服务器主机名以及可选的URI资源等
作用范围:通常在location块中进行设置
负载均衡
指令:upstream指令可以实现负载均衡,在该指令中能够配置负载服务器组
- 配置方式:目前负载均衡有4种典型的配置方式
| 配置方式 | 说明 |
|---|---|
| 轮询方式 | 负载均衡默认设置方式,每个请求按照时间顺序逐一分配到不同的后端服务器进行处理,如果有服务器宕机,会自动剔除 |
| 权重方式 | 利用weight指定轮询的权重比率,与访问率成正比,用于后端服务器性能不均的情况 |
| ip_hash方式 | 每个请求按访问IP的hash结果分配,这样可以使每个访客固定访问一个后端服务器,可以解决Session共享的问题 |
| 第三方模块 | 采用fair时,按照每台服务器的响应时间来分配请求,响应时间短的优先分配;若第三方模块采用url_hash时,按照访问url的hash值来分配请求 |
配置nginx反向代理,使用nginx1、APP1、APP2三个容器
使用php-apache镜像启动APP1和APP2两个容器
1) docker network create –subnet=172.18.0.0/16 cluster //创建docker网络1
2
3
4
5
6
7
8
9[root@localhost ~]# docker network create --subnet=172.18.0.0/16 cluster
93cf616f5b6466f3872a697e7246d525173405659d659f775584460cc523fc19
[root@localhost ~]# docker network ls
NETWORK ID NAME DRIVER SCOPE
5b668484dc8f bridge bridge local
93cf616f5b64 cluster bridge local
f2010c589fe5 host host local
3e84fc461677 none null local
[root@localhost ~]#
2) 启动容器APP1,设定地址为172.18.0.111, 启动容器APP2,设定地址为172.18.0.112
docker run -d --privileged --net cluster --ip 172.18.0.111 --name APP1 php-apache /usr/sbin/initdocker run -d --privileged --net cluster --ip 172.18.0.112 --name APP2 php-apache /usr/sbin/init1
2
3
4
5
6
7
8
9[root@localhost ~]# docker run -d --privileged --net cluster --ip 172.18.0.111 --name APP1 php-apache /usr/sbin/init
0119783e023dbd322e6598c4556743408fb2fda176b26406b8c80d3d982bf02e
[root@localhost ~]# docker run -d --privileged --net cluster --ip 172.18.0.112 --name APP2 php-apache /usr/sbin/init
f2744c76c1759187788620e84705a0905b1021da4d987620b96cc0f3b4d2eac8
[root@localhost ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
f2744c76c175 php-apache "/usr/sbin/init" 4 seconds ago Up 2 seconds APP2
0119783e023d php-apache "/usr/sbin/init" 20 seconds ago Up 18 seconds APP1
[root@localhost ~]#
3) 配置容器APP1,编辑首页内容为“site1”1
2
3
4
5
6
7
8
9
10[root@localhost ~]# docker exec -it f27 /bin/bash
[root@f2744c76c175 /]# vim /var/www/html/index.html
[root@f2744c76c175 /]# systemctl status httpd
● httpd.service - The Apache HTTP Server
Loaded: loaded (/usr/lib/systemd/system/httpd.service; disabled; vendor preset: disabled)
Drop-In: /usr/lib/systemd/system/httpd.service.d
└─php-fpm.conf
Active: inactive (dead)
Docs: man:httpd.service(8)
[root@f2744c76c175 /]# systemctl start httpd
4) 配置容器APP1,编辑首页内容为“site2”1
2
3
4[root@localhost ~]# docker exec -it 011 /bin/bash
[root@0119783e023d /]# vim /var/www/html/index.html
[root@0119783e023d /]# systemctl start httpd
[root@0119783e023d /]#
5)在宿主机访问1
2
3
4
5[root@localhost ~]# curl 172.18.0.111
This is site1!
[root@localhost ~]# curl 172.18.0.112
This is site2!
[root@localhost ~]#
使用nginx镜像启动nginx1容器,配置反向代理
1) 启动容器nginx1,设定地址为172.18.0.11docker run -d --privileged --net cluster --ip 172.18.0.11 -p 80:80 --name nginx1 nginx /usr/sbin/init1
2
3
4[root@localhost ~]# docker run -d --privileged --net cluster --ip 172.18.0.11 -p 80:80 --name nginx1 nginx /usr/sbin/init
b0db3efdfe817b3df2557ef598e6bf709a5cabcfe2122d40caf344ee96075aac
[root@localhost ~]# docker exec -it b0d /bin/bash
[root@b0db3efdfe81 /]#
2) 在容器nginx1编辑/etc/nginx/nginx.conf文件,重新启动nginx服务
配置两台虚拟主机1
2
3
4
5
6
7
8
9
10
11
12
13
14server {
listen 80;
server_name site1.test.com;
location / {
proxy_pass http://172.18.0.111;
}
}
server {
listen 80;
server_name site2.test.com;
location / {
proxy_pass http://172.18.0.112;
}
3) }在主机编辑hosts文件1
2
3宿主机的IP地址 site1.test.com
宿主机的IP地址 site2.test.com
宿主机的IP地址 www.test.com
4) 在主机使用浏览器访问site1.test.com
5) 在主机使用浏览器访问site2.test.com
配置nginx负载均衡,使用nginx1、APP1、APP2三个容器
保持以上三个容器不变
使用nginx1容器,配置nginx一般轮询负载均衡
1) 在容器nginx1编辑/etc/nginx/nginx.conf文件,重新启动nginx服务
配置 www.test.com虚拟主机1
2
3
4
5
6
7server {
listen 80;
server_name www.test.com;
location / {
proxy_pass http://APP;
}
}
配置负载均衡服务器组1
2
3
4upstream APP {
server 172.18.0.111;
server 172.18.0.112;
}
2) 在主机使用浏览器访问 www.test.com并不断刷新

使用nginx1容器,配置nginx IP哈希轮询
1) 在容器nginx1编辑/etc/nginx/conf.d/default.conf文件,重新启动nginx服务
配置 www.test.com虚拟主机1
2
3
4
5
6
7server {
listen 80;
server_name www.test.com;
location / {
proxy_pass http://APP;
}
}
配置负载均衡服务器组1
2
3
4
5upstream APP {
ip_hash;
server 172.18.0.111;
server 172.18.0.112;
}
2) 在不同ip主机使用浏览器访问 www.test.com