Q-learning is a simple yet quite powerful algorithm to create a cheat sheet for our agent. This helps the agent figure out exactly which action to perform.
But what if this cheatsheet is too long? Imagine an environment with 10,000 states and 1,000 actions per state. This would create a table of 10 million cells. Things will quickly get out of control!
It is pretty clear that we can’t infer the Q-value of new states from already explored states. This presents two problems:
First, the amount of memory required to save and update that table would increase as the number of states increases Second, the amount of time required to explore each state to create the required Q-table would be unrealistic Here’s a thought – what if we approximate these Q-values with machine learning models such as a neural network? Well, this was the idea behind DeepMind’s algorithm that led to its acquisition by Google for 500 million dollars!
In deep Q-learning, we use a neural network to approximate the Q-value function. The state is given as the input and the Q-value of all possible actions is generated as the output. The comparison between Q-learning & deep Q-learning is wonderfully illustrated below:

So, what are the steps involved in reinforcement learning using deep Q-learning networks (DQNs)?
All the past experience is stored by the user in memory The next action is determined by the maximum output of the Q-network The loss function here is mean squared error of the predicted Q-value and the target Q-value – Q*. This is basically a regression problem. However, we do not know the target or actual value here as we are dealing with a reinforcement learning problem. Going back to the Q-value update equation derived fromthe Bellman equation. we have:
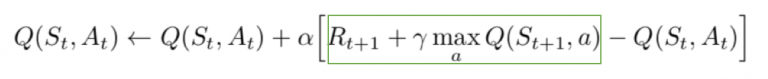
The section in green represents the target. We can argue that it is predicting its own value, but since R is the unbiased true reward, the network is going to update its gradient using backpropagation to finally converge.
So far, this all looks great. We understood how neural networks can help the agent learn the best actions. However, there is a challenge when we compare deep RL to deep learning (DL):
Non-stationary or unstable target: Let us go back to the pseudocode for deep Q-learning: deep q-learning
As you can see in the above code, the target is continuously changing with each iteration. In deep learning, the target variable does not change and hence the training is stable, which is just not true for RL.
To summarise, we often depend on the policy or value functions in reinforcement learning to sample actions. However, this is frequently changing as we continuously learn what to explore. As we play out the game, we get to know more about the ground truth values of states and actions and hence, the output is also changing.
So, we try to learn to map for a constantly changing input and output. But then what is the solution?

Since the same network is calculating the predicted value and the target value, there could be a lot of divergence between these two. So, instead of using 1one neural network for learning, we can use two.
We could use a separate network to estimate the target. This target network has the same architecture as the function approximator but with frozen parameters. For every C iterations (a hyperparameter), the parameters from the prediction network are copied to the target network. This leads to more stable training because it keeps the target function fixed (for a while):
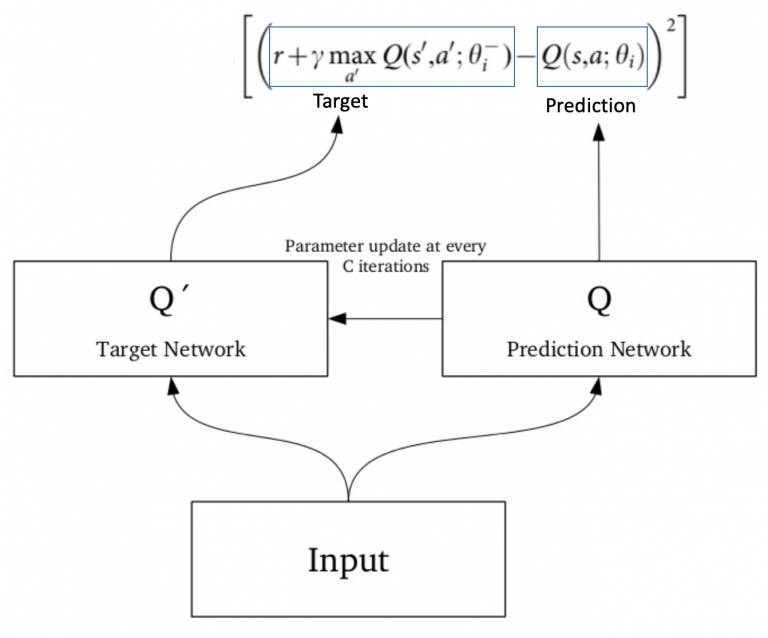
What does the above statement mean? Instead of running Q-learning on state/action pairs as they occur during simulation or the actual experience, the system stores the data discovered for [state, action, reward, next_state] – in a large table.
Let’s understand this using an example.
Suppose we are trying to build a video game bot where each frame of the game represents a different state. During training, we could sample a random batch of 64 frames from the last 100,000 frames to train our network. This would get us a subset within which the correlation amongst the samples is low and will also provide better sampling efficiency.
Putting it all Together The concepts we have learned so far? They all combine to make the deep Q-learning algorithm that was used to achive human-level level performance in Atari games (using just the video frames of the game).
I have listed the steps involved in a deep Q-network (DQN) below:
* Preprocess and feed the game screen (state s) to our DQN, which will return the Q-values of all possible actions in the state
* Select an action using the epsilon-greedy policy. With the probability epsilon, we select a random action a and with probability 1-epsilon, we select an action that has a maximum Q-value, such as a = argmax(Q(s,a,w))
* Perform this action in a state s and move to a new state s’ to receive a reward. This state s’ is the preprocessed image of the next game screen. We store this transition in our replay buffer as <s,a,r,s’>
* Next, sample some random batches of transitions from the replay buffer and calculate the loss
* It is known that: which is just the squared difference between target Q and predicted Q
* Perform gradient descent with respect to our actual network parameters in order to minimize this loss
* After every C iterations, copy our actual network weights to the target network weights
* Repeat these steps for M number of episodes
[1] Playing Atari with Deep Reinforcement Learning, Mnih et al, 2013. Algorithm: DQN.
[2] Deep Recurrent Q-Learning for Partially Observable MDPs, Hausknecht and Stone, 2015. Algorithm: Deep Recurrent Q-Learning.
[3] Dueling Network Architectures for Deep Reinforcement Learning, Wang et al, 2015. Algorithm: Dueling DQN.
[4] Deep Reinforcement Learning with Double Q-learning, Hasselt et al 2015. Algorithm: Double DQN.
[5] Prioritized Experience Replay, Schaul et al, 2015. Algorithm: Prioritized Experience Replay (PER).
[6] Rainbow: Combining Improvements in Deep Reinforcement Learning, Hessel et al, 2017. Algorithm: Rainbow DQN.