![]()
中文 | English
📖 中文文档 | 📖 English Documentation
⭐ If you like this project, please click the "Star" button in the upper right corner to support us. Your support is our motivation to move forward!
EvalScope is a one-stop LLM evaluation framework built by the ModelScope Community. Just one command to start — it supports model capability evaluation, inference performance stress testing, and result visualization.
pip install evalscope
evalscope eval --model your-model-name --api-url $OPENAI_API_BASE_URL --api-key $OPENAI_API_KEY --eval-type openai_api --datasets gsm8k --limit 5- 📚 Comprehensive Evaluation Benchmarks: Built-in multiple industry-recognized evaluation benchmarks including MMLU, C-Eval, GSM8K, and more.
- 🧩 Multi-modal and Multi-domain Support: Supports evaluation of various model types including Large Language Models (LLM), Vision Language Models (VLM), Embedding, Reranker, AIGC, and more.
- 🚀 Multi-backend Integration: Seamlessly integrates multiple evaluation backends including OpenCompass, VLMEvalKit, RAGEval to meet different evaluation needs.
- ⚡ Inference Performance Testing: Provides powerful model service stress testing tools, supporting multiple performance metrics such as TTFT, TPOT.
- 📊 Interactive Reports: Provides WebUI visualization interface, supporting multi-dimensional model comparison, report overview and detailed inspection.
- ⚔️ Arena Mode: Supports multi-model battles (Pairwise Battle), intuitively ranking and evaluating models.
- 🔧 Highly Extensible: Developers can easily add custom datasets, models and evaluation metrics.
EvalScope provides an interactive Web Dashboard for multi-dimensional model comparison and in-depth analysis.
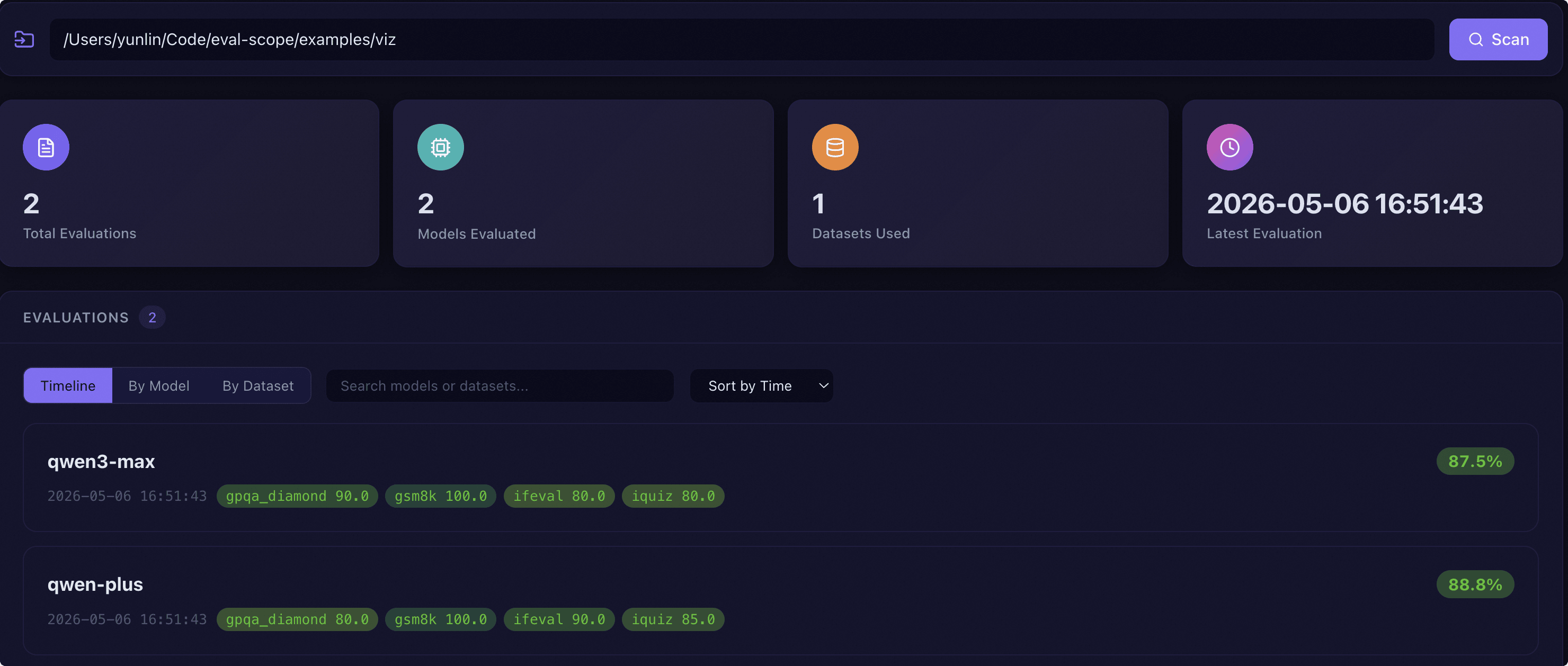
Dashboard Overview |
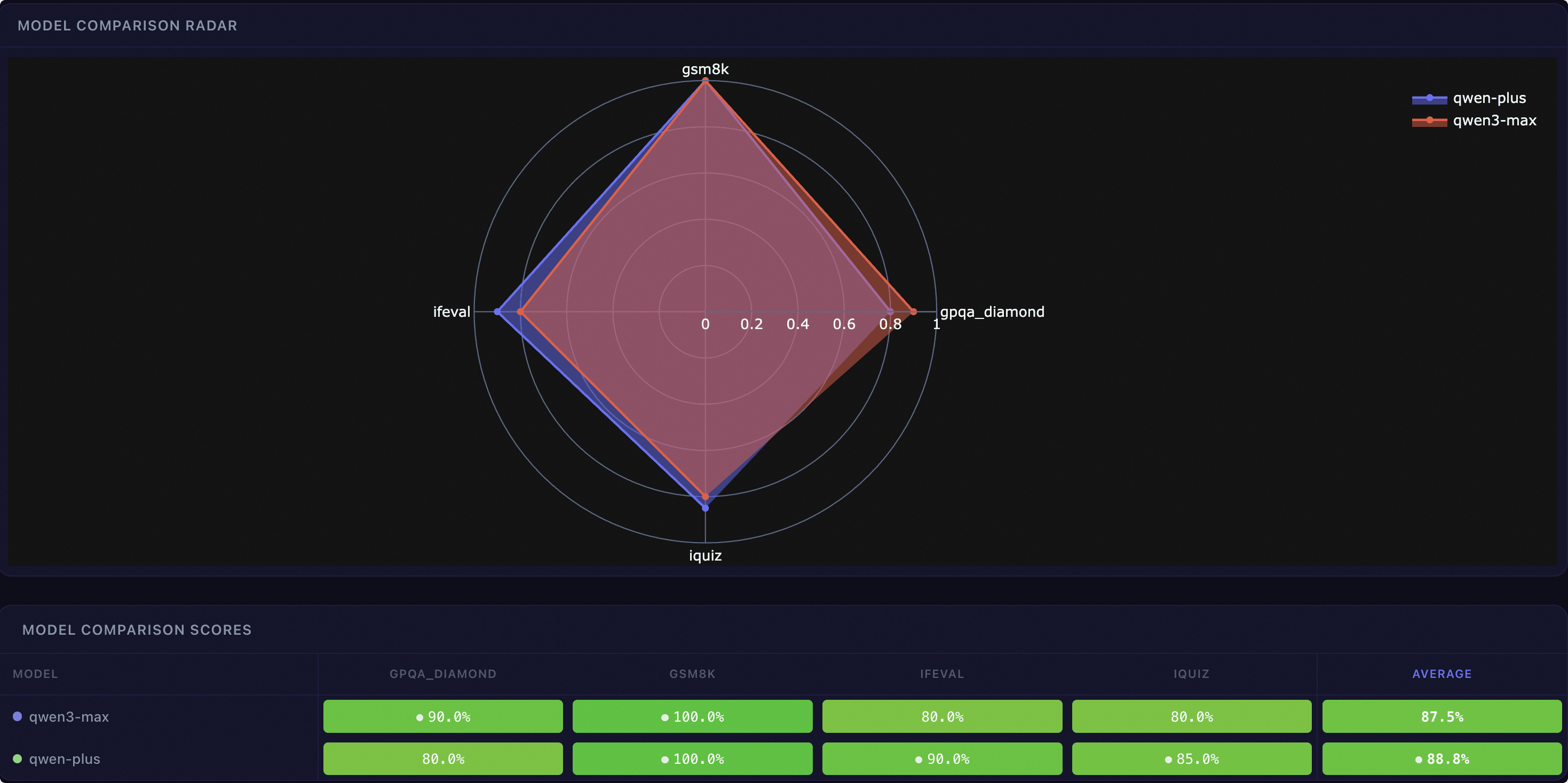
Model Comparison |
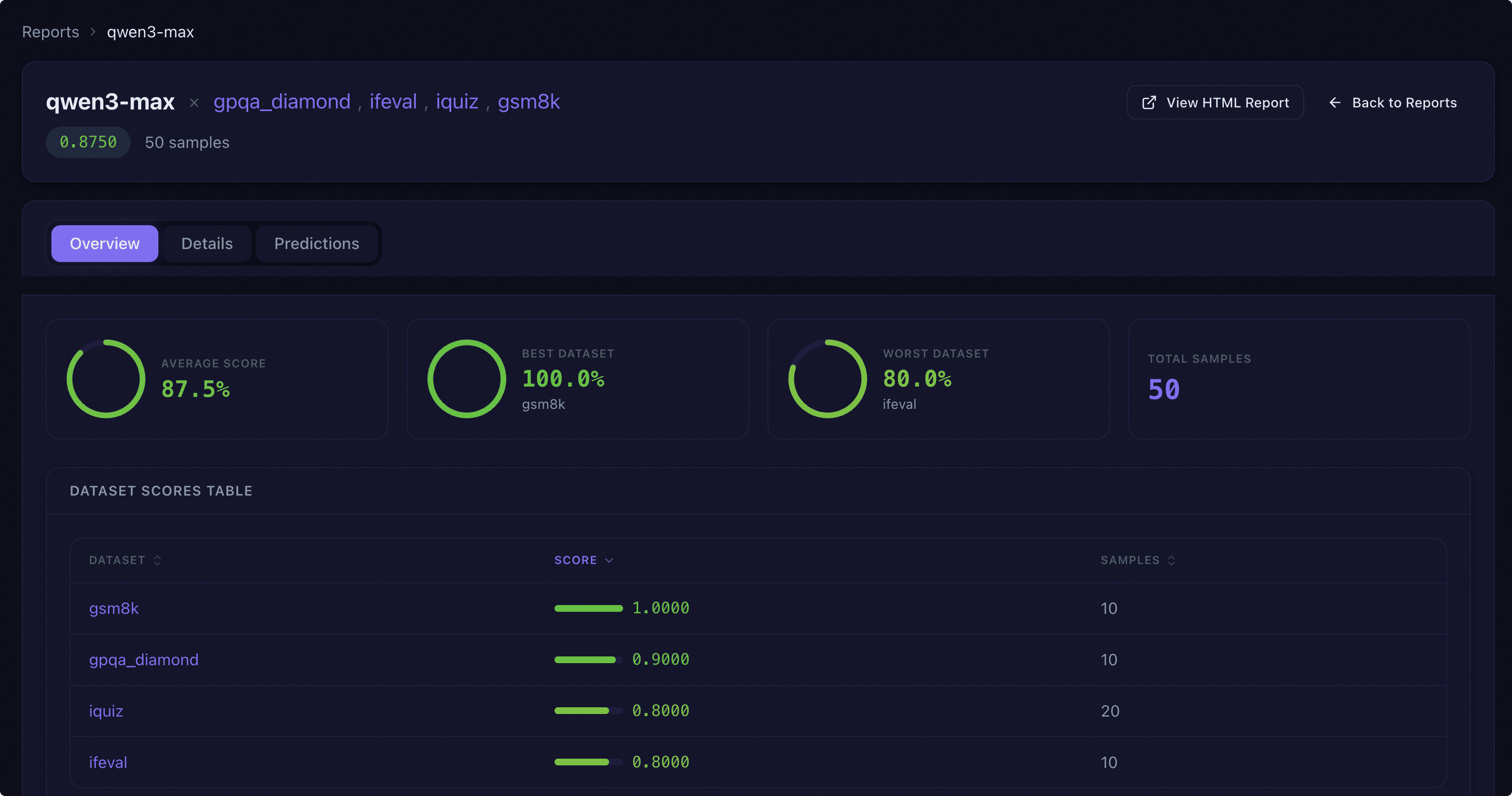
Report Overview |
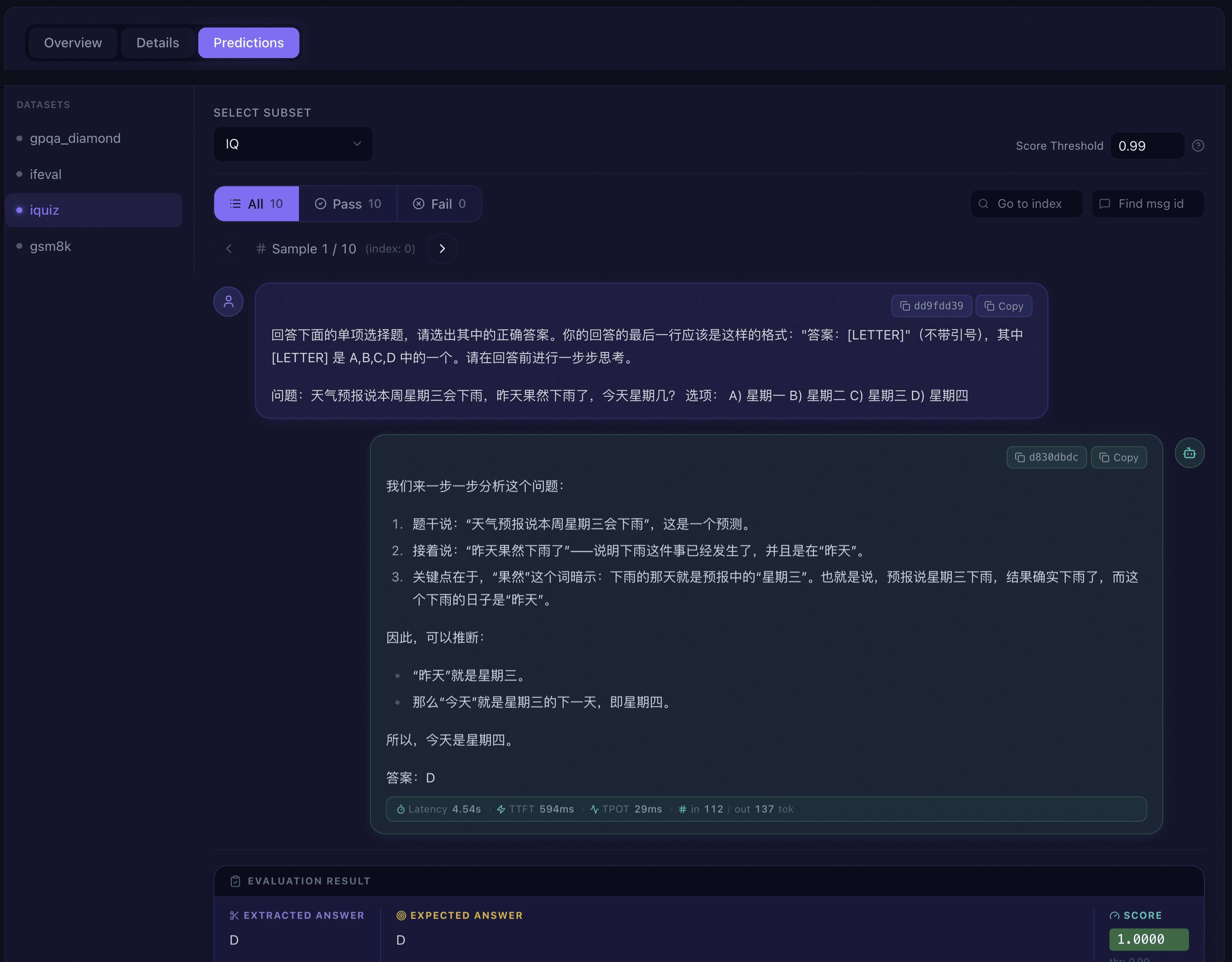
Prediction Details |
For details, please refer to 📖 Visualizing Evaluation Results.
- 🔥 [2026.05.08] Partnered with LightSeek to launch TokenSpeed, a speed-of-light LLM inference engine for agentic workloads. EvalScope provides the SWE-smith benchmarking pipeline — using real coding-agent traces to measure per-GPU throughput (TPM) and per-user latency (TPS) — serving as the official benchmark tool for TokenSpeed performance evaluation. Refer to the SWE-smith usage guide to get started.
- 🔥 [2026.05.07] Replaced the Gradio-based WebUI with a new React + Vite web interface for better performance and user experience.
- 🔥 [2026.04.23] Added support for recording performance (perf) metrics during evaluation tasks, enabling simultaneous tracking of model accuracy and inference efficiency metrics such as TTFT, TPOT, and throughput in a single evaluation run.
- 🔥 [2026.04.17] Added support for multi-turn conversation performance stress testing, enabling load testing of dialogue-based model services with multi-turn context. Refer to the usage documentation.
- 🔥 [2026.04.10] Added support for TIR-Bench (Thinking-with-Images Reasoning Benchmark), a multimodal benchmark evaluating agentic visual reasoning capabilities of vision-language models.
- 🔥 [2026.03.24] Added support for Agent Skill. Any agent model that supports Skill/Tool calling can use natural language to drive EvalScope for model evaluation, performance benchmarking, and result visualization.
- 🔥 [2026.03.09] Added support for evaluation progress tracking and HTML format visualization report generation.
More historical updates
- 🔥 [2026.03.02] Added support for Anthropic Claude API evaluation. Use
--eval-type anthropic_apito evaluate models via Anthropic API service. - 🔥 [2026.02.03] Comprehensive update to dataset documentation, adding data statistics, data samples, usage instructions and more.
- 🔥 [2026.01.13] Added support for Embedding and Rerank model service stress testing.
- 🔥 [2025.12.26] Added support for Terminal-Bench-2.0, which evaluates AI Agent performance on 89 real-world multi-step terminal tasks.
- 🔥 [2025.12.18] Added support for SLA auto-tuning model API services.
- 🔥 [2025.12.16] Added support for audio evaluation benchmarks such as Fleurs, LibriSpeech; added support for multilingual code evaluation benchmarks such as MultiplE, MBPP.
- 🔥 [2025.12.02] Added support for custom multimodal VQA evaluation; added support for visualizing model service stress testing in ClearML.
- 🔥 [2025.11.26] Added support for OpenAI-MRCR, GSM8K-V, MGSM, MicroVQA, IFBench, SciCode benchmarks.
- 🔥 [2025.11.18] Added support for custom Function-Call (tool invocation) datasets to test whether models can timely and correctly call tools.
- 🔥 [2025.11.14] Added support for SWE-bench_Verified, SWE-bench_Lite, SWE-bench_Verified_mini code evaluation benchmarks.
- 🔥 [2025.11.12] Added
pass@k,vote@k,pass^kand other metric aggregation methods; added support for multimodal evaluation benchmarks such as A_OKVQA, CMMU, ScienceQA, V*Bench. - 🔥 [2025.11.07] Added support for τ²-bench, an extended and enhanced version of τ-bench that includes a series of code fixes and adds telecom domain troubleshooting scenarios.
- 🔥 [2025.10.30] Added support for BFCL-v4, enabling evaluation of agent capabilities including web search and long-term memory.
- 🔥 [2025.10.27] Added support for LogiQA, HaluEval, MathQA, MRI-QA, PIQA, QASC, CommonsenseQA and other evaluation benchmarks. Thanks to @penguinwang96825 for the code implementation.
- 🔥 [2025.10.26] Added support for Conll-2003, CrossNER, Copious, GeniaNER, HarveyNER, MIT-Movie-Trivia, MIT-Restaurant, OntoNotes5, WNUT2017 and other Named Entity Recognition evaluation benchmarks. Thanks to @penguinwang96825 for the code implementation.
- 🔥 [2025.10.21] Optimized sandbox environment usage in code evaluation, supporting both local and remote operation modes.
- 🔥 [2025.10.20] Added support for evaluation benchmarks including PolyMath, SimpleVQA, MathVerse, MathVision, AA-LCR; optimized evalscope perf performance to align with vLLM Bench.
- 🔥 [2025.10.14] Added support for OCRBench, OCRBench-v2, DocVQA, InfoVQA, ChartQA, and BLINK multimodal image-text evaluation benchmarks.
- 🔥 [2025.09.22] Code evaluation benchmarks (HumanEval, LiveCodeBench) now support running in a sandbox environment.
- 🔥 [2025.09.19] Added support for multimodal image-text evaluation benchmarks including RealWorldQA, AI2D, MMStar, MMBench, and OmniBench, as well as pure text evaluation benchmarks such as Multi-IF, HealthBench, and AMC.
- 🔥 [2025.09.05] Added support for vision-language multimodal model evaluation tasks, such as MathVista and MMMU.
- 🔥 [2025.09.04] Added support for image editing task evaluation, including the GEdit-Bench benchmark.
- 🔥 [2025.08.22] Version 1.0 Refactoring. Break changes, please refer to.
- 🔥 [2025.07.18] The model stress testing now supports randomly generating image-text data for multimodal model evaluation.
- 🔥 [2025.07.16] Support for τ-bench has been added.
- 🔥 [2025.07.14] Support for "Humanity's Last Exam" (Humanity's-Last-Exam).
- 🔥 [2025.07.03] Refactored Arena Mode.
- 🔥 [2025.06.28] Optimized custom dataset evaluation; enhanced LLM judge usage.
- 🔥 [2025.06.19] Added support for the BFCL-v3 benchmark.
- 🔥 [2025.06.02] Added support for the Needle-in-a-Haystack test.
- 🔥 [2025.05.29] Added support for two long document evaluation benchmarks: DocMath and FRAMES.
- 🔥 [2025.05.16] Model service performance stress testing now supports setting various levels of concurrency.
- 🔥 [2025.05.13] Added support for the ToolBench-Static dataset, DROP and Winogrande benchmarks.
- 🔥 [2025.04.29] Added Qwen3 Evaluation Best Practices.
- 🔥 [2025.04.27] Support for text-to-image evaluation.
- 🔥 [2025.04.10] Model service stress testing tool now supports the
/v1/completionsendpoint. - 🔥 [2025.04.08] Support for evaluating embedding model services compatible with the OpenAI API has been added.
- 🔥 [2025.03.27] Added support for AlpacaEval and ArenaHard evaluation benchmarks.
- 🔥 [2025.03.20] The model inference service stress testing now supports generating prompts of specified length using random values.
- 🔥 [2025.03.13] Added support for the LiveCodeBench code evaluation benchmark.
- 🔥 [2025.03.11] Added support for the SimpleQA and Chinese SimpleQA evaluation benchmarks.
- 🔥 [2025.03.07] Added support for the QwQ-32B model evaluation.
- 🔥 [2025.03.04] Added support for the SuperGPQA dataset.
- 🔥 [2025.03.03] Added support for evaluating the IQ and EQ of models.
- 🔥 [2025.02.27] Added support for evaluating the reasoning efficiency of models.
- 🔥 [2025.02.25] Added support for MuSR and ProcessBench benchmarks.
- 🔥 [2025.02.18] Supports the AIME25 dataset.
- 🔥 [2025.02.13] Added support for evaluating DeepSeek distilled models.
- 🔥 [2025.01.20] Support for visualizing evaluation results.
- 🔥 [2025.01.07] Native backend: Support for model API evaluation.
- 🔥🔥 [2024.12.31] Support for adding benchmark evaluations.
- 🔥 [2024.12.13] Model evaluation optimization.
- 🔥 [2024.11.26] The model inference service performance evaluator has been completely refactored.
- 🔥 [2024.10.31] The best practice for evaluating Multimodal-RAG has been updated.
- 🔥 [2024.10.23] Supports multimodal RAG evaluation.
- 🔥 [2024.10.8] Support for RAG evaluation.
- 🔥 [2024.09.18] Documentation added blog module.
- 🔥 [2024.09.12] Support for LongWriter evaluation.
- 🔥 [2024.08.30] Support for custom dataset evaluations.
- 🔥 [2024.08.20] Updated the official documentation.
- 🔥 [2024.08.09] Simplified the installation process.
- 🔥 [2024.07.31] Important change: The package name
llmuseshas been changed toevalscope. - 🔥 [2024.07.26] Support for VLMEvalKit as a third-party evaluation framework.
- 🔥 [2024.06.29] Support for OpenCompass as a third-party evaluation framework.
- 🔥 [2024.06.13] EvalScope integrates with SWIFT; Integrated the Agent evaluation dataset ToolBench.
pip install evalscopeFor detailed installation instructions (source install, extra dependencies, etc.), please refer to the 📖 Installation Guide.
Supports any OpenAI API-compatible model service. Just set $OPENAI_API_BASE_URL and $OPENAI_API_KEY and you are ready to go:
evalscope eval \
--model your-model-name \
--api-url $OPENAI_API_BASE_URL \
--api-key $OPENAI_API_KEY \
--eval-type openai_api \
--datasets gsm8k arc \
--limit 5Evaluate a local model (auto-downloaded from ModelScope):
evalscope eval \
--model Qwen/Qwen2.5-0.5B-Instruct \
--datasets gsm8k arc \
--limit 5from evalscope import run_task, TaskConfig
task_cfg = TaskConfig(
model='your-model-name',
api_url='https://your-openai-compatible-endpoint/v1',
api_key='your_api_key',
eval_type='openai_api',
datasets=['gsm8k', 'arc'],
limit=5
)
run_task(task_cfg)💡 Tip: run_task also supports dictionaries, YAML or JSON files as configuration.
Using Python Dictionary
from evalscope.run import run_task
task_cfg = {
'model': 'Qwen/Qwen2.5-0.5B-Instruct',
'datasets': ['gsm8k', 'arc'],
'limit': 5
}
run_task(task_cfg=task_cfg)Using YAML File (config.yaml)
model: Qwen/Qwen2.5-0.5B-Instruct
datasets:
- gsm8k
- arc
limit: 5from evalscope.run import run_task
run_task(task_cfg="config.yaml")After evaluation completion, you will see a report in the terminal in the following format:
+-----------------------+----------------+-----------------+-----------------+---------------+-------+---------+
| Model Name | Dataset Name | Metric Name | Category Name | Subset Name | Num | Score |
+=======================+================+=================+=================+===============+=======+=========+
| Qwen2.5-0.5B-Instruct | gsm8k | AverageAccuracy | default | main | 5 | 0.4 |
+-----------------------+----------------+-----------------+-----------------+---------------+-------+---------+
| Qwen2.5-0.5B-Instruct | ai2_arc | AverageAccuracy | default | ARC-Easy | 5 | 0.8 |
+-----------------------+----------------+-----------------+-----------------+---------------+-------+---------+
| Qwen2.5-0.5B-Instruct | ai2_arc | AverageAccuracy | default | ARC-Challenge | 5 | 0.4 |
+-----------------------+----------------+-----------------+-----------------+---------------+-------+---------+
Launch the visualization dashboard:
pip install 'evalscope[service]'
evalscope serviceVisit http://127.0.0.1:9000 to open the visualization interface.
You can fine-tune model loading, inference, and dataset configuration through command line parameters.
evalscope eval \
--model Qwen/Qwen3-0.6B \
--model-args '{"revision": "master", "precision": "torch.float16", "device_map": "auto"}' \
--generation-config '{"do_sample":true,"temperature":0.6,"max_tokens":512}' \
--dataset-args '{"gsm8k": {"few_shot_num": 0, "few_shot_random": false}}' \
--datasets gsm8k \
--limit 10--model-args: Model loading parameters such asrevision,precision, etc.--generation-config: Model generation parameters such astemperature,max_tokens, etc.--dataset-args: Dataset configuration parameters such asfew_shot_num, etc.
For details, please refer to 📖 Complete Parameter Guide.
Arena mode evaluates model performance through pairwise battles between models, providing win rates and rankings, perfect for horizontal comparison of multiple models.
# Example evaluation results
Model WinRate (%) CI (%)
------------ ------------- ---------------
qwen2.5-72b 69.3 (-13.3 / +12.2)
qwen2.5-7b 50 (+0.0 / +0.0)
qwen2.5-0.5b 4.7 (-2.5 / +4.4)
For details, please refer to 📖 Arena Mode Usage Guide.
EvalScope allows you to easily add and evaluate your own datasets. For details, please refer to 📖 Custom Dataset Evaluation Guide.
EvalScope provides a powerful stress testing tool for evaluating the performance of large language model services.
- Key Metrics: Supports throughput (Tokens/s), first token latency (TTFT), token generation latency (TPOT), etc.
- Result Recording: Supports recording results to
wandbandswanlab. - Speed Benchmarks: Can generate speed benchmark results similar to official reports.
For details, please refer to 📖 Performance Testing Usage Guide.

EvalScope supports launching evaluation tasks through third-party evaluation frameworks (we call them "backends") to meet diverse evaluation needs.
- Native: EvalScope's default evaluation framework with comprehensive functionality.
- OpenCompass: Focuses on text-only evaluation. 📖 Usage Guide
- VLMEvalKit: Focuses on multi-modal evaluation. 📖 Usage Guide
- RAGEval: Focuses on RAG evaluation, supporting Embedding and Reranker models. 📖 Usage Guide
- Third-party Evaluation Tools: Supports evaluation tasks like ToolBench.
🏛️ Overall Architecture
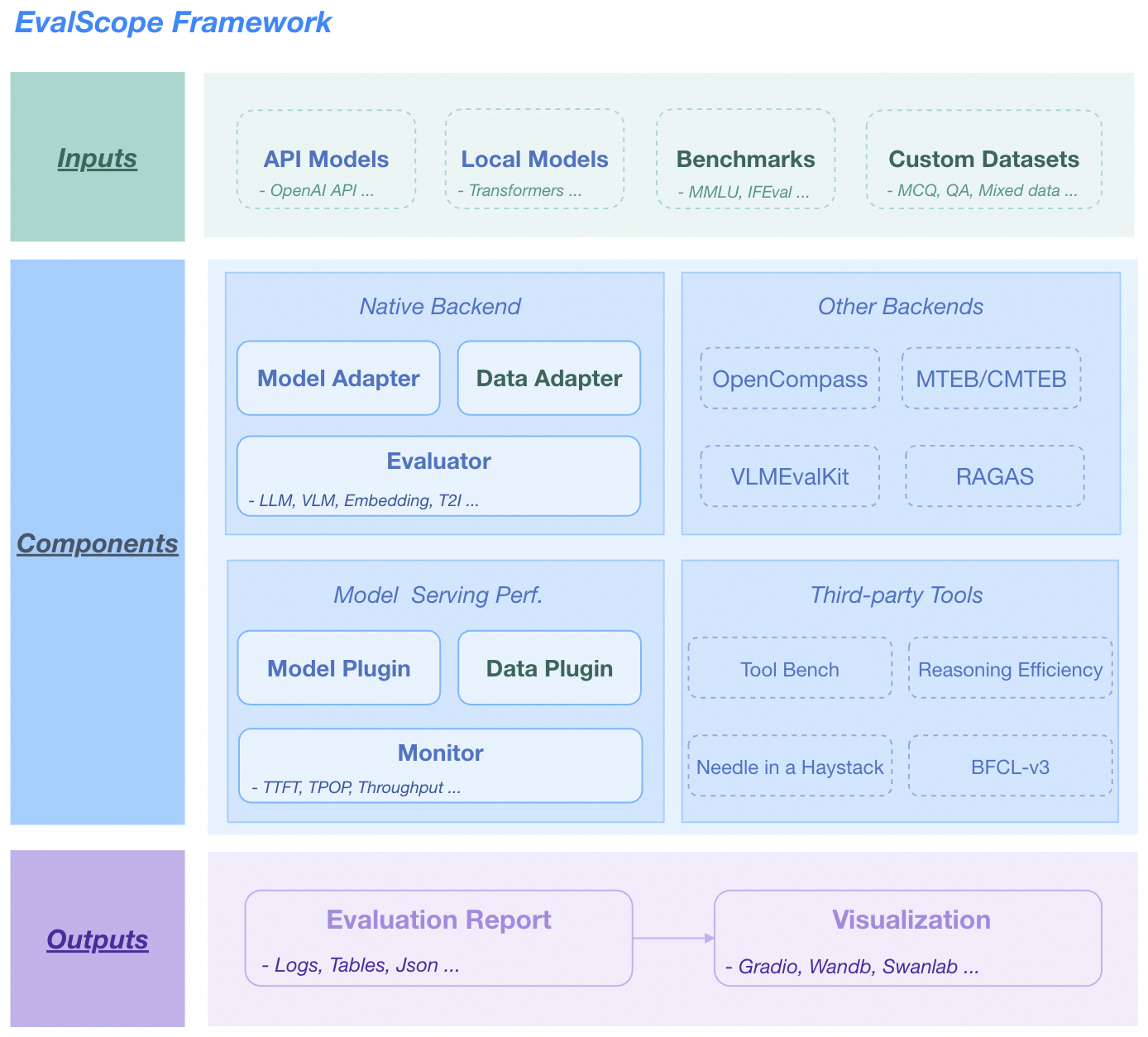
EvalScope Overall Architecture.
-
Input Layer
- Model Sources: API models (OpenAI API), Local models (ModelScope)
- Datasets: Standard evaluation benchmarks (MMLU/GSM8k etc.), Custom data (MCQ/QA)
-
Core Functions
- Multi-backend Evaluation: Native backend, OpenCompass, MTEB, VLMEvalKit, RAGAS
- Performance Monitoring: Supports multiple model service APIs and data formats, tracking TTFT/TPOP and other metrics
- Tool Extensions: Integrates Tool-Bench, Needle-in-a-Haystack, etc.
-
Output Layer
- Structured Reports: Supports JSON, Table, Logs
- Visualization Platform: Supports Web Dashboard, Wandb, SwanLab
Welcome to join our community to communicate with other developers and get help.
| Discord Group | WeChat Group | DingTalk Group |
|---|---|---|
 |
 |
 |
We welcome any contributions from the community! If you want to add new evaluation benchmarks, models, or features, please refer to our Contributing Guide.
Thanks to all developers who have contributed to EvalScope!
|
|
|---|
If you use EvalScope in your research, please cite our work:
@misc{evalscope_2024,
title={{EvalScope}: Evaluation Framework for Large Models},
author={ModelScope Team},
year={2024},
url={https://github.com/modelscope/evalscope}
}