线程池、Future、CompletableFuture和CompletionService这些并发工具都帮助开发站在任务角度解决并发问题,而非纠结于线程之间协作的细节,如线程之间如何实现等待、通知。
- 简单的并行任务:线程池+Future
- 任务之间有聚合关系:AND、OR聚合,都可以CompletableFuture一发入魂
- 批量的并行任务:CompletionService一把梭
并发编程主要为如下层面问题:
- 分工
- 协作
- 互斥
关注任务时,你会发现你的视角已脱离于并发编程细节,而使用现实世界思维模式,类比现实世界的分工,线程池、Future、CompletableFuture和CompletionService都可列为分工问题。
简单并行任务:
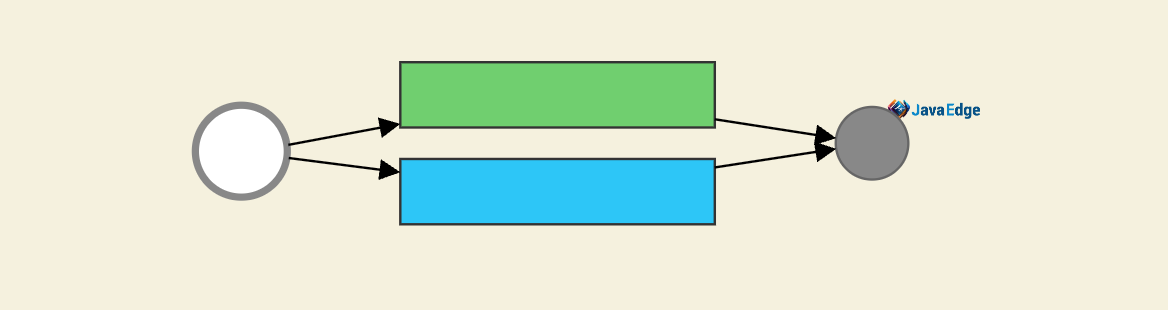
聚合任务:
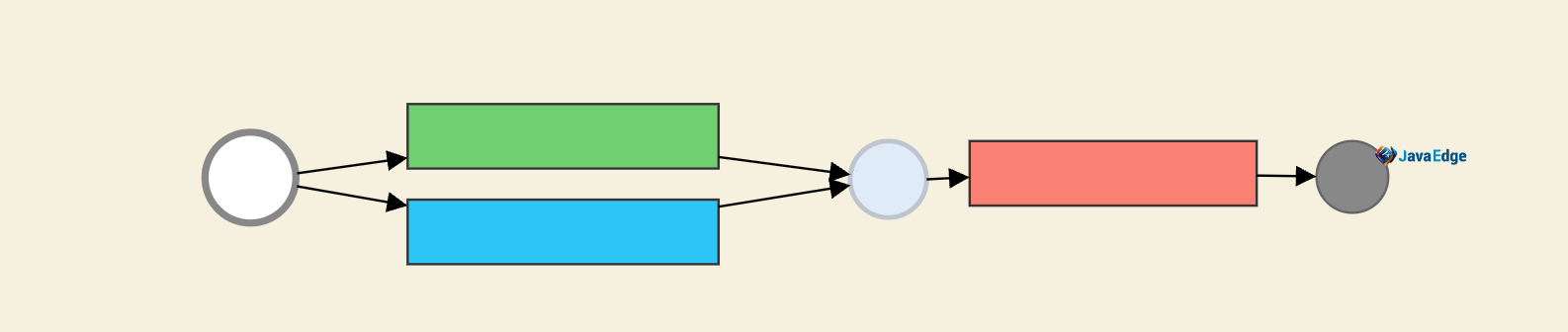
批量并行任务:
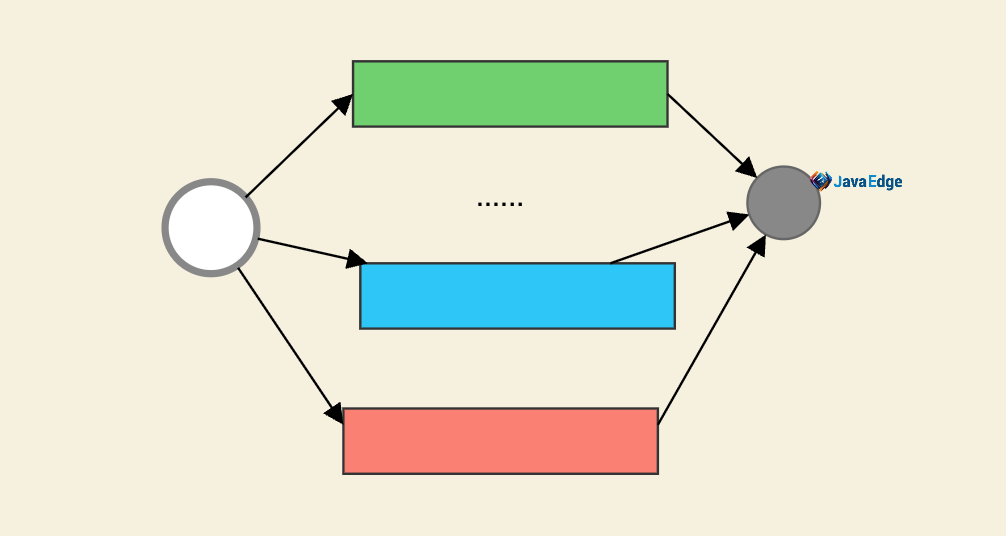
这三种任务模型,基本覆盖日常工作中的并发场景,但不全面,还有
把一个复杂问题分解成多个相似子问题,再把子问题分解成更小子问题,直到子问题简单到可直接求解。每个问题对应一个任务,所以对问题的分治,就是对任务的分治。
-
任务分解:将任务迭代地分解为子任务,直至子任务可计算出结果
-
结果合并:逐层合并子任务的执行结果,直至获得最终结果
Fork/Join是并行计算框架,以支持分治任务模型:
- Fork,对应分治任务模型里的任务分解
- Join,对应结果合并
Fork/Join计算框架主要包含:
- 分治任务的线程池,ForkJoinPool
- 分治任务,ForkJoinTask
这俩关系类似ThreadPoolExecutor和Runnable,都是提交任务到线程池,只不过分治任务有自己独特的任务类型ForkJoinTask。
// since JDK7
public abstract class ForkJoinTask<V> implements Future<V>, Serializable {public final ForkJoinTask<V> fork() {
Thread t;
if ((t = Thread.currentThread()) instanceof ForkJoinWorkerThread)
((ForkJoinWorkerThread)t).workQueue.push(this);
else
ForkJoinPool.common.externalPush(this);
return this;
}异步执行一个子任务
public final V join() {
int s;
if ((s = doJoin() & DONE_MASK) != NORMAL)
reportException(s);
return getRawResult();
}阻塞当前线程,等待子任务的执行结果。
ForkJoinTask有俩子类,都是递归处理分治任务,都定义抽象方法compute():
无返回值
public abstract class RecursiveAction extends ForkJoinTask<Void> {
private static final long serialVersionUID = 5232453952276485070L;
/**
* The main computation performed by this task.
*/
protected abstract void compute();compute()有返回值
public abstract class RecursiveTask<V> extends ForkJoinTask<V> {
private static final long serialVersionUID = 5232453952276485270L;
/**
* The result of the computation.
*/
V result;
/**
* The main computation performed by this task.
* @return the result of the computation
*/
protected abstract V compute();这俩类依旧还是抽象类,要定义子类具体实现。
public class ForkJoinTaskExample {
public static void main(String[] args) {
// 创建分治任务线程池
ForkJoinPool forkJoinPool = new ForkJoinPool(4);
// 创建分治任务
Fibonacci fib = new Fibonacci(30);
// 启动分治任务
Integer result = forkJoinPool.invoke(fib);
System.out.println(result);
}
/**
* 数列的递归任务 需要有返回值
*/
static class Fibonacci extends RecursiveTask<Integer> {
final int n;
Fibonacci(int n) {
this.n = n;
}
@Override
protected Integer compute() {
if (n <= 1) {
return n;
}
Fibonacci f1 = new Fibonacci(n - 1);
// 创建子任务
f1.fork();
Fibonacci f2 = new Fibonacci(n - 2);
// 等待子任务结果,并合并结果
return f2.compute() + f1.join();
}
}
}Fork/Join核心就是ForkJoinPool。ThreadPoolExecutor本质是生产者-消费者实现,内部有个任务队列,作为生产者和消费者的通信媒介。ThreadPoolExecutor可以有多个工作线程,这些工作线程共享任务队列。
ForkJoinPool本质也是一个生产者-消费者的实现,但更智能:
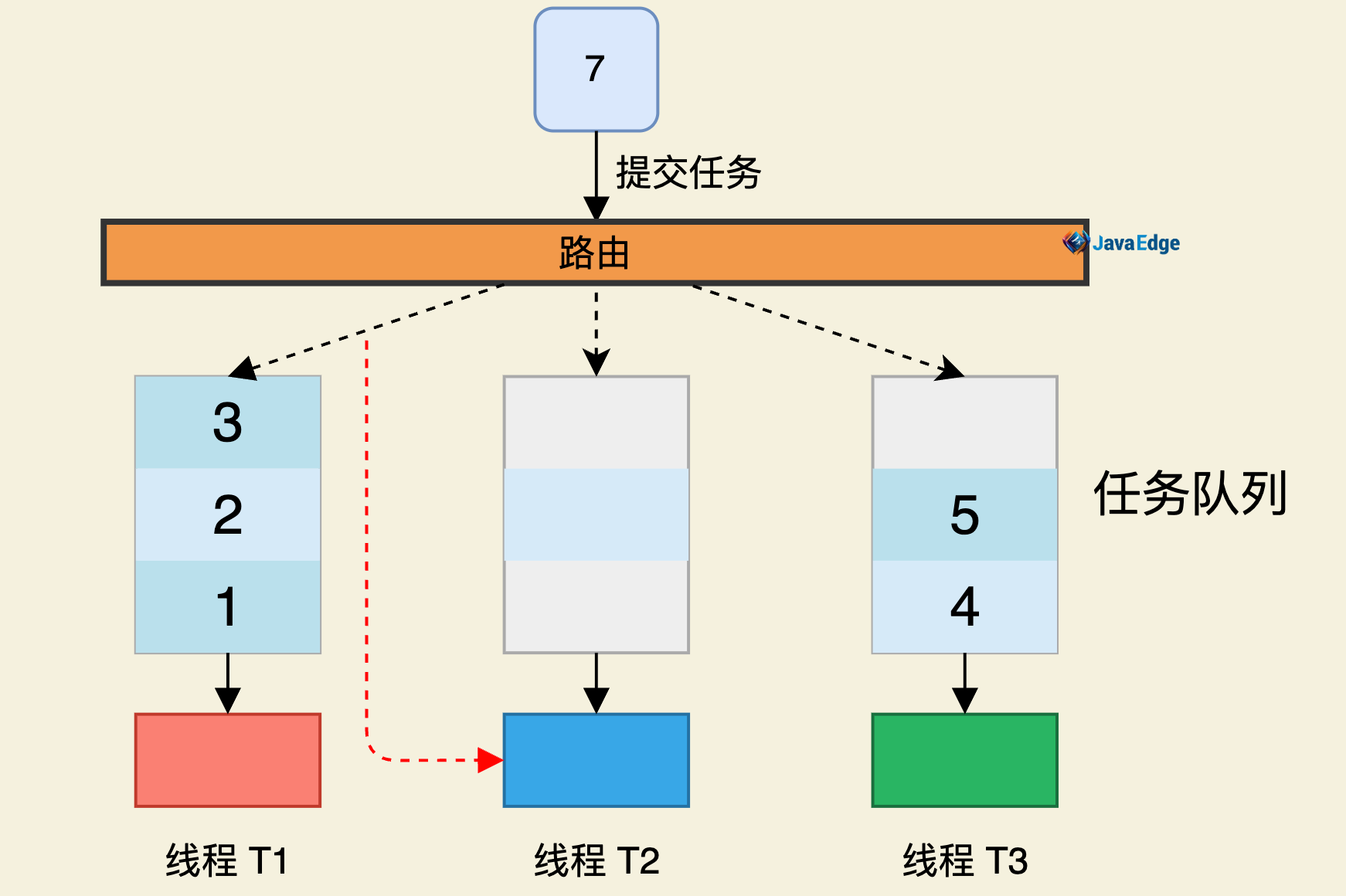
- ThreadPoolExecutor内部仅一个任务队列
- 而ForkJoinPool内部有多个任务队列
当调用ForkJoinPool#invoke()或submit()提交任务时,ForkJoinPool把任务通过路由规则提交到一个任务队列,若任务执行过程中会创建出子任务,则子任务会提交到工作线程对应的任务队列。
若工作线程对应的任务队列空,是不是就没活干?No!ForkJoinPool有“任务窃取”机制,若工作线程空闲,它会“窃取”其他工作任务队列里的任务,如上图的线程T2对应任务队列已空。它会“窃取”线程T1对应的任务队列的任务。这样所有工作线程都不会闲。
ForkJoinPool的任务队列采用的是双端队列,工作线程正常获取任务和“窃取任务”分别从任务队列不同的端消费,这也能避免很多不必要的数据竞争。
ForkJoinPool支持任务窃取机制,能够让所有线程的工作量基本公平,不会出现线程有的很忙,有的一直在摸鱼,是个公正的领导。Java8的Stream API里面并行流也是基于ForkJoinPool。
默认,所有的并行流计算都共享一个ForkJoinPool,这个共享的ForkJoinPool的默认线程数是CPU核数;若所有并行流计算都是CPU密集型,完全没有问题,但若存在I/O密集型并行流计算,那很可能因为一个很慢的I/O计算而拖慢整个系统的性能。所以建议用不同ForkJoinPool执行不同类型的计算任务。
参考: